With every click, swipe, and transaction, an ocean of data is generated, which is both an opportunity and a challenge for businesses today. While the sheer volume of information opens doors to valuable insights, it also brings hurdles like integration complexities, inconsistent quality, and the demand for real-time processing.
The existing data engineering methods are somewhat struggling to keep up with growing demands. Issues such as data silos, inconsistent formats, and the ever-looming threat of security breaches further complicate the data landscape.
This has sparked the need for smarter, more efficient solutions. So, here we bring you the latest trends shaping data engineering in 2025 and show how they are enabling enterprises to realize the true power of their data.
The Evolving Landscape of Data Engineering
Businesses rely on data to make decisions, predict trends, and create personalized customer experiences. But as data grows in scale, speed, and complexity, managing it effectively has become more challenging. These changes are forcing everyone to rethink how to handle data workflows and strategies.
One major shift is the overwhelming amount of data being generated. From IoT devices and social media platforms to enterprise systems, businesses are flooded with streams of structured and unstructured data. Traditional methods of processing and analyzing data just cannot keep up, often leading to delays and bottlenecks. To stay competitive, companies are seeking solutions that are more agile, scalable, and cost-efficient, such as data platform modernization and cloud-native architectures.
Another challenge is the increasing complexity of data systems. Today, data comes from a diverse range of sources, each with its own formats and schemas, making integration and management harder. This leads to issues like data silos, inconsistent quality, and delays in extracting actionable insights. Add to it the growing demands for real-time analytics, enhanced security, and strict compliance with regulations, and it is clear why the data engineering landscape is becoming increasingly intricate.
Healthcare, for example, has to deal with strict regulations like HIPAA, which makes secure and reliable data management a must. Retail relies heavily on real-time analytics to personalize customer experiences and keep inventory moving in fast-paced markets. And in finance, the stakes are even higher, with constant security threats and fraud risks driving the need for advanced systems to protect sensitive data. These examples show just how varied and demanding modern data challenges can be, highlighting the need for tailored solutions.
Fortunately, advanced technologies are stepping up to tackle these challenges head-on. Trends like the rise of zero-ETL architectures, real-time data processing, and AI-powered data tools are not only addressing these pain points but also opening up new possibilities for businesses.
Top Data Engineering Trends to Look for in 2025
Let us examine data engineering trends, to discover how they are pushing the boundaries of what data can do.
1. Adoption of Open Table Formats
Managing large datasets has always been tricky. What happens when you need to update or delete records in massive data lakes? Without proper support, you risk data corruption or incomplete transactions.
Open table format (OTF) solves this with ACID (Atomicity, Consistency, Isolation, Durability) transactions, ensuring reliable updates, inserts, and deletes, even at scale. These capabilities provide the foundational integrity required to manage data lakes as robustly as traditional data warehouses.
For insights on building a warehouse, explore our blog on best practices for data warehousing.
Key Features:
-
Schema Evolution: With businesses constantly transforming, your data structure needs to adapt. OTFs let you add, rename, or remove columns without breaking workflows, ensuring data remains accessible and usable.
-
Time Travel: Need to debug an issue from last week? Query your data as it existed at any point in time without restoring backups. This is especially valuable for auditing, compliance, and root-cause analysis.
-
Engine Agnosticism: Open table formats are designed to be interoperable with tools like Spark, Trino, and Flink, allowing flexibility without locking into a specific vendor’s ecosystem.
A Quiet Revolution in Data Lakes
OTFs bring the power of SQL functionality directly to data lakes, bridging the gap between flexibility and control. Among these, Apache Iceberg is rapidly gaining traction due to its performance, interoperability, and support from both open-source communities and commercial vendors.
According to reports, 31% of companies are already using Iceberg, with an additional 29% planning to adopt it within the next three years, surpassing other table formats like Delta Lake.
By embracing open table formats, you can future-proof your data infrastructure, empowering teams to work faster and smarter while preserving full control over data. If you are building a modern data platform, this trend should be at the top of your list.
If you are looking to build a data lake that aligns with these modern trends, check out our comprehensive guide to data lake architecture.
2. Domain-Specific and Specialized Language Models
This year, the focus in AI is shifting from general-purpose large language models (LLMs) to domain-specific and specialized language models. These tailored models are designed to excel in particular fields like healthcare, law, or finance, offering more accurate and relevant outputs compared to their generalized counterparts.
Why the Shift?
General LLMs are trained on vast datasets covering a wide range of topics, which can sometimes lead to outputs that lack the depth required for specialized tasks. On the other hand, domain-specific models are fine-tuned on data pertinent to a particular field, enabling them to understand and generate content with greater precision and context.
For instance, in the medical field, a specialized model trained on biomedical literature can interpret complex terminology and provide insights that a general model might miss. This specificity enhances the model's utility in real-world applications where accuracy is crucial.
Advantages of Specialized Models
-
Enhanced Accuracy: By focusing on domain-relevant data, these models reduce the likelihood of errors, which makes them more reliable for professional use.
-
Efficiency: Specialized models often require fewer computational resources compared to large, general-purpose models, making them more accessible and cost-effective.
-
Improved User Experience: Engaging with a model that understands the specific jargon and context of a domain leads to more satisfying and productive interactions.
Real-World Applications
In 2024, companies like Bayer collaborated with a tech giant to develop AI models fine-tuned with industry-specific data. These models, designed to address agricultural and crop protection queries, are now available for licensing, demonstrating the commercial viability and demand for specialized AI solutions.
Moreover, the development of Small Language Models (SLMs) has gained traction. These models, such as Phi-3 and TinyLlama, offer many capabilities of larger models but are optimized for efficiency, making them suitable for mobile and low-power devices.
3. Integration of DataOps and MLOps Practices
Another trend set to redefine data engineering in 2025 is the integration of DataOps and MLOps. This fusion aims to streamline the entire data and machine learning lifecycle, enhancing collaboration, automation, and efficiency across teams.
Understanding DataOps and MLOps
DataOps is a methodology that focuses on improving the communication, integration, and automation of data flows between data managers and data consumers. It emphasizes collaboration, data quality, and rapid delivery of data-driven insights.
An extension of the DevOps practice, MLOps manages the machine learning lifecycle, including model development, deployment, monitoring, and governance. It ensures that ML models are production-ready and maintain their performance over time.
The Power of Integration
Combining DataOps and MLOps creates a unified framework that addresses challenges in deploying and maintaining data-intensive applications. This integration offers several key benefits:
-
Enhanced Collaboration: By breaking down silos between data engineering, data science, and IT operations, teams can work more cohesively, leading to faster development cycles and more reliable outputs.
-
Automation and Efficiency: Automating data pipelines and ML workflows reduces manual intervention, minimizes errors, and accelerates time-to-market for data products.
-
Improved Data Quality and Model Performance: Continuous monitoring ensures that data remains accurate and models perform optimally, adapting to any changes in data patterns or business requirements.
As organizations strive to become more data-driven, adopting integrated DataOps and MLOps practices will be crucial. Leveraging data engineering consulting services can further streamline this process, providing the expertise needed to design and implement effective workflows. This approach not only enhances operational efficiency but also ensures that data and machine learning initiatives are scalable, sustainable, and aligned with business objectives.
4. Implementation of Data Mesh and Data Fabric Architectures
With the rapid evolution of data strategies, data mesh and data fabric continue to be central to the conversation. While both have gained traction as ways to manage the increasing complexity of modern data ecosystems, their trajectories are markedly different.
Data Mesh: Flexibility Meets Reality
First introduced by Zhamak Dehghani, data mesh quickly became popular for its promise of decentralized ownership, giving domain teams greater control over their data. Each team treats their data as a product, focusing on usability, quality, and alignment with business needs. This approach empowers teams to innovate without waiting on a central bottleneck.
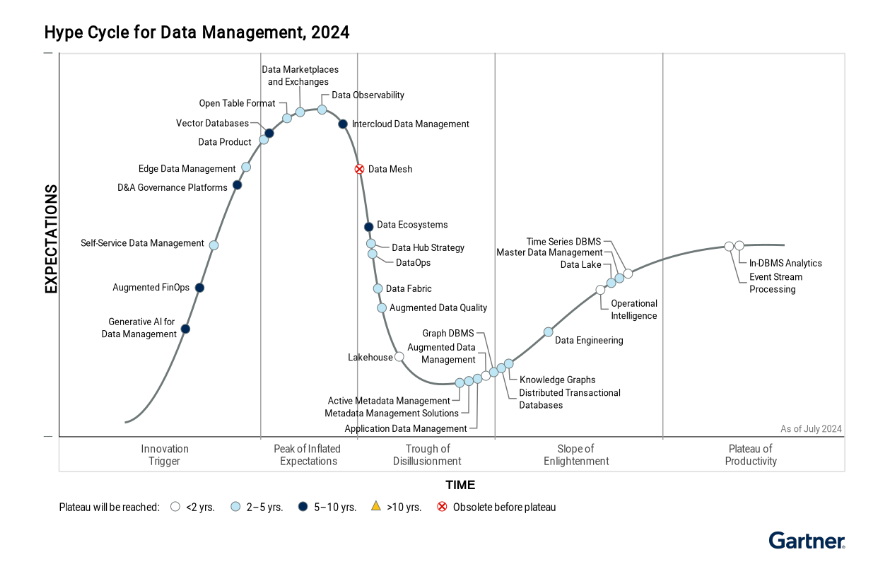
However, according to Gartner’s Hype Cycle, data mesh is now on a downward trend, with signs it may have peaked before reaching widespread adoption.
Data Fabric: Rising to meet new demands
On the other hand, data fabric is emerging as a robust solution to address siloed data systems. Unlike data mesh, data fabric focuses on creating an integrated architecture that connects data across platforms, whether on-premises, in the cloud, or at the edge.
Gartner predicts that data fabric will take 2-5 years to mature but sees it as a critical technology for addressing data silos and automating processes like schema alignment and profiling new data sources.
Despite its promise, data fabric adoption is still in its early stages. But as siloed stacks and unpreparedness for generative AI drive organizations to seek new solutions, data fabric is poised to step into the spotlight.
How they work together
Rather than choosing between data mesh and data fabric, businesses can leverage both. Data mesh provides structure and accountability, while data fabric ensures seamless data flow and integration across the organization.
Here is an analogy: if your data ecosystem were a city, data mesh would be the zoning laws assigning ownership of specific areas (domains), and data fabric would be the interconnected roads and utilities, ensuring everything runs smoothly.
Organizations that embrace this combined approach can:
-
Break Down Silos: Data mesh decentralizes control, while data fabric integrates everything for a unified view.
-
Accelerate Insights: Real-time access and domain ownership lead to faster, more accurate decision-making.
-
Enhance Governance: Both approaches focus on maintaining quality, compliance, and security, a must in today’s data-driven world.
While data mesh provides a cultural and organizational framework for decentralization, data fabric delivers the technological backbone to connect and automate data ecosystems.
5. Expansion of Cloud-Native Data Engineering
Heading into 2025, cloud-native data engineering has gained momentum as organizations prioritize scalability, flexibility, and cost efficiency. These architectures, built to harness the power of cloud platforms, are redefining how businesses handle and process their data.
Understanding Cloud-Native Data Engineering
Cloud-native data engineering involves building and deploying data systems specifically designed for cloud platforms. This approach uses cloud services to enhance scalability, performance, and agility, which further enables organizations to handle increasing data volumes and complex processing requirements efficiently.
Key Drivers of Cloud-Native Adoption
-
Scalability and Flexibility: Cloud-native solutions allow you to scale resources up or down based on demand, ensuring optimal performance without the need for significant upfront investments.
-
Cost Efficiency: Adopting cloud-native platforms means you only pay for what you need, reducing upfront costs and freeing up budget for innovation and growth.
-
Enhanced Collaboration: Cloud platforms facilitate seamless collaboration among distributed teams, providing access to data and tools from anywhere.
The adoption of cloud-native data engineering is evident across various industries. For instance, companies are increasingly relying on data migration consulting to transition to cloud-based solutions. This enables them to leverage pre-built services, elastic resources, and automated infrastructure management. As a result, businesses can focus more on their core data engineering tasks.
Additionally, the integration of AI and machine learning into cloud-native data platforms is enhancing data processing capabilities, enabling more intelligent and responsive data systems.
For a comparison of leading cloud platforms, see our in-depth review of AWS, Azure, and Google Cloud Platform.
6. Embracing Zero-ETL Architectures
Another trend making waves in 2025 is the rise of Zero-ETL, a concept that is all about simplifying how data is integrated and analyzed. Instead of relying on ETL pipelines, Zero-ETL offers a more direct approach, making data access faster, easier, and less complicated.
Understanding Zero-ETL
For years, ETL has been the go-to method for managing data. You pull data from different sources (Extract), clean it up and reformat it (Transform), and finally store it in a data warehouse or lake (Load). While this process works, it can be slow, resource-heavy, and a headache to maintain, especially when you need real-time insights.
Zero-ETL architectures aim to address these challenges by enabling direct integrations between data sources and analytical platforms. This approach reduces data movement, lowers latency, and allows for real-time data access, enhancing prompt decision-making capabilities.
Key Drivers of Zero-ETL Adoption
-
Real-Time Analytics: Businesses increasingly require immediate insights to stay competitive. Zero-ETL facilitates real-time data access, eliminating the delays inherent in traditional ETL processes.
-
Operational Efficiency: By reducing the need for complex data pipelines, you can lower operational costs and allocate resources more effectively.
-
Data Consistency: Direct integrations help maintain data consistency and integrity, as there are fewer stages where errors can be introduced.
Leading cloud service providers are driving the adoption of Zero-ETL solutions. For instance, AWS introduced integrations between Amazon Aurora and Amazon Redshift, allowing data to be automatically replicated and queried without the need for manual ETL processes. This development streamlines data workflows and accelerates the availability of insights.
Similarly, platforms like Google BigQuery offer capabilities that enable direct querying of data from various sources, further reducing the dependence on ETL pipelines.
Hiccups in the process
While Zero-ETL architectures offer significant advantages, they also present challenges:
-
Complex Integrations: Establishing seamless connections between diverse data sources and analytical tools can be complex and may require specialized solutions.
-
Data Governance: Ensuring data quality, security, and compliance remains crucial, even when traditional ETL processes are bypassed.
-
Scalability: You must assess whether Zero-ETL solutions can scale effectively to meet your growing data needs.
By enabling more efficient and real-time data access, businesses can enhance their analytical capabilities and respond more swiftly to market dynamics. However, careful consideration of the associated challenges is essential to fully leverage the benefits of this emerging trend.
7. The Rise of Synthetic Data in Data Engineering
Synthetic data refers to artificially generated data that mimics real-world datasets while addressing challenges such as privacy, bias, and data scarcity. In contrast to traditional data collected from users or systems, synthetic data is created using algorithms, often based on generative AI models. This trend is rapidly gaining traction as organizations face increasing pressure to balance innovation with compliance and privacy.
The Need For Synthetic Data
-
Overcoming Data Scarcity: In domains like healthcare and autonomous vehicles, access to real-world data can be limited or costly. Synthetic data fills these gaps by simulating scenarios that are difficult to capture.
-
Enhancing Privacy: With stricter privacy regulations like GDPR and CCPA, companies must safeguard sensitive data. Synthetic datasets provide a compliant alternative for AI training without exposing actual user information.
-
Bias Reduction: Synthetic data can help address biases in real-world data by ensuring diversity and balance, improving the fairness and reliability of machine learning models.
Applications Across Industries
-
Healthcare: Simulating patient data to train AI models without violating privacy regulations.
-
Autonomous Vehicles: Generating scenarios for testing AI systems in edge cases like extreme weather or unusual traffic patterns.
-
Retail and E-Commerce: Creating realistic shopping behavior data to optimize recommendation engines.
Challenges in Adopting Synthetic Data
One of the key hurdles is validation, as it is crucial to ensure that synthetic data accurately reflects real-world patterns and behaviors. If the data fails to meet this standard, its usefulness for training models or generating insights diminishes significantly.
Another challenge lies in the complexity of creating high-quality synthetic data. This process demands advanced tools and specialized expertise, which may not be readily available to all organizations. Besides, acceptance can be a barrier, as teams may hesitate to fully trust synthetic data as a reliable alternative to real-world datasets.
Having said that, synthetic data is expected to become a core asset for organizations seeking to scale AI-driven initiatives.
8. Advancements in Real-Time Data Processing
Businesses today need to make decisions faster than ever, and real-time data processing is stepping up to meet that challenge. Thanks to recent advancements, real-time analytics is becoming more efficient, accessible, and impactful than ever.
Streaming Data Platforms
Streaming data platforms have taken center stage, empowering organizations to process and act on information in real time. Unlike batch processing, streaming data enables businesses to gain insights and respond to events as they happen—a critical advantage in today’s fast-paced digital economy.
Edge Computing and 5G Integration
Combining edge computing with 5G technology has taken real-time data processing to the next level. By processing data closer to its source, edge computing reduces delays and provides immediate insights.
The rollout of 5G networks has provided the high-speed, low-latency connectivity required for edge computing applications. With 5G, data can be transmitted between devices and edge servers at blazing speeds, making real-time processing feasible.
AI and Machine Learning Integration
Integrating AI and machine learning into real-time data systems makes them smarter and more adaptable. These technologies predict trends, automate decisions, and adjust to changing data patterns in real time, helping businesses stay one step ahead of their competitors.
The advancements in real-time data processing are set to continue, driven by the increasing demand for instant insights and the proliferation of data-generating devices. Organizations that leverage these technologies will be better positioned to make data-driven decisions, respond to market changes promptly, and maintain a competitive edge in their respective industries.
9. Standardization of Data Contracts
Data contracts act as clear agreements between data producers and consumers, defining what the data should look like, how it should behave, and the responsibilities of each party involved. They are essentially the rules of the game that everyone agrees to before playing.
Why does this matter? Because without these guardrails, teams often end up wasting time debugging pipelines, handling schema mismatches, or reconciling conflicting data definitions. With data contracts, you establish a shared language across teams, ensuring smoother workflows and fewer unpleasant surprises.
How Do They Work?
Suppose you are a data producer creating a stream of customer orders. A data contract might specify that each order record includes fields like order_id, customer_name, and order_date, with clear definitions for each. It can also outline validation rules, such as order_id being unique and order_date following a specific date format.
The Benefits
-
Fewer Breakages: Downstream teams can confidently rely on consistent data structures, reducing pipeline failures.
-
Improved Collaboration: Developers, analysts, and data engineers work better together when everyone knows what to expect.
-
Faster Debugging: Clear agreements make it easier to pinpoint issues when things go wrong.
As organizations increasingly adopt complex data ecosystems, standardizing data contracts will become essential for scaling operations without losing efficiency.
10. Strengthening Data Governance and Privacy Measures
With time, the emphasis on data governance and privacy has intensified, driven by evolving regulations and heightened consumer awareness. Organizations are recognizing that robust data governance frameworks are essential not only for compliance but also for building trust and ensuring data integrity.
Dynamic Regulatory Landscape
The regulatory environment is becoming increasingly stringent. In 2024, several U.S. states, including New Jersey, Kentucky, and New Hampshire, enacted comprehensive privacy laws, compelling businesses to enhance their data protection measures.
Internationally, countries like Australia and Malaysia updated their data protection laws with new enforcement powers and child-focused provisions, reflecting a global trend towards stricter data privacy regulations.
Integration of AI and Automation
The integration of AI and automation into data governance processes is on the rise as well. These technologies facilitate real-time data monitoring, anomaly detection, and compliance management, further enabling organizations to proactively address data quality issues and adhere to regulatory requirements.
Consumer Trust and Ethical Data Use
Consumers are becoming more conscious of how their data is collected and utilized. Organizations are responding by implementing transparent data practices and emphasizing ethical data use to build and maintain trust. This shift is not only a response to regulatory demands but also a strategic move to enhance brand reputation and customer loyalty.
As we move forward, the focus on data governance and privacy is expected to intensify. You will need to invest in advanced data governance tools, encourage a culture of data responsibility, and stay abreast of regulatory developments to navigate the complexities of the data landscape effectively.
Final Thoughts: Embrace the Future of Data Engineering
Looking ahead, it is clear that trends like data fabric, real-time data processing, AI integration, and zero-ETL architectures are evolving into essential strategies for businesses aiming to stay competitive in the data-driven era.
But navigating this dynamic landscape can be complex. This is where we can make all the difference. At Closeloop, we empower businesses with our expert data engineering consulting services, simplifying the intricacies of handling any volume of data. From breaking down silos to improving data accessibility, our evolutionary approach accelerates time-to-market and reduces costs.
Our team of expert data engineers will help you leverage these cutting-edge data engineering trends to streamline operations, enhance decision-making, and future-proof your data infrastructure. Whether you need guidance on implementing data warehouse solutions or automating your pipelines, we have got you covered.
Let’s turn your data complexity into an opportunity!
Author

Saurabh Sharma

VP of Engineering
VP of Engineering at Closeloop, a seasoned technology guru and a rational individual, who we call the captain of the Closeloop team. He writes about technology, software tools, trends, and everything in between. He is brilliant at the coding game and a go-to person for software strategy and development. He is proactive, analytical, and responsible. Besides accomplishing his duties, you can find him conversing with people, sharing ideas, and solving puzzles.
Stay abreast of what's trending in the world of technology
Cost Breakdown to Build a Custom Logistics Software: Complete Guide
Global logistics is transforming faster than ever. Real-time visibility, automation, and AI...

Logistics Software Development Guide: Types, Features, Industry Solutions & Benefits
The logistics and transportation industry is evolving faster than ever. It’s no longer...

From Hurdle to Success: Conquering the Top 5 Cloud Adoption Challenges
Cloud adoption continues to accelerate across enterprises, yet significant barriers persist....

Gen AI for HR: Scaling Impact and Redefining the Workplace
The human resources landscape stands at a critical inflection point. Generative AI in HR has...

