Modern data teams are facing a structural problem where analytics systems are getting smarter, but transactional systems haven’t caught up. Meanwhile, expectations are rising across the board with business users wanting real-time insights, applications demanding low-latency updates, and developers left managing duplicate data across warehouses, lakes, and OLTP systems.
Historically, you had to choose. If you needed fast writes and updates, you would build on a traditional database. If you needed reporting and advanced analytics, you moved data to a data warehouse or lake. That split between transactional (OLTP) and analytical (OLAP) workloads has defined enterprise architecture for decades. It also created major inefficiencies such as pipeline complexity, stale dashboards, missed insights, and fragile data syncs.
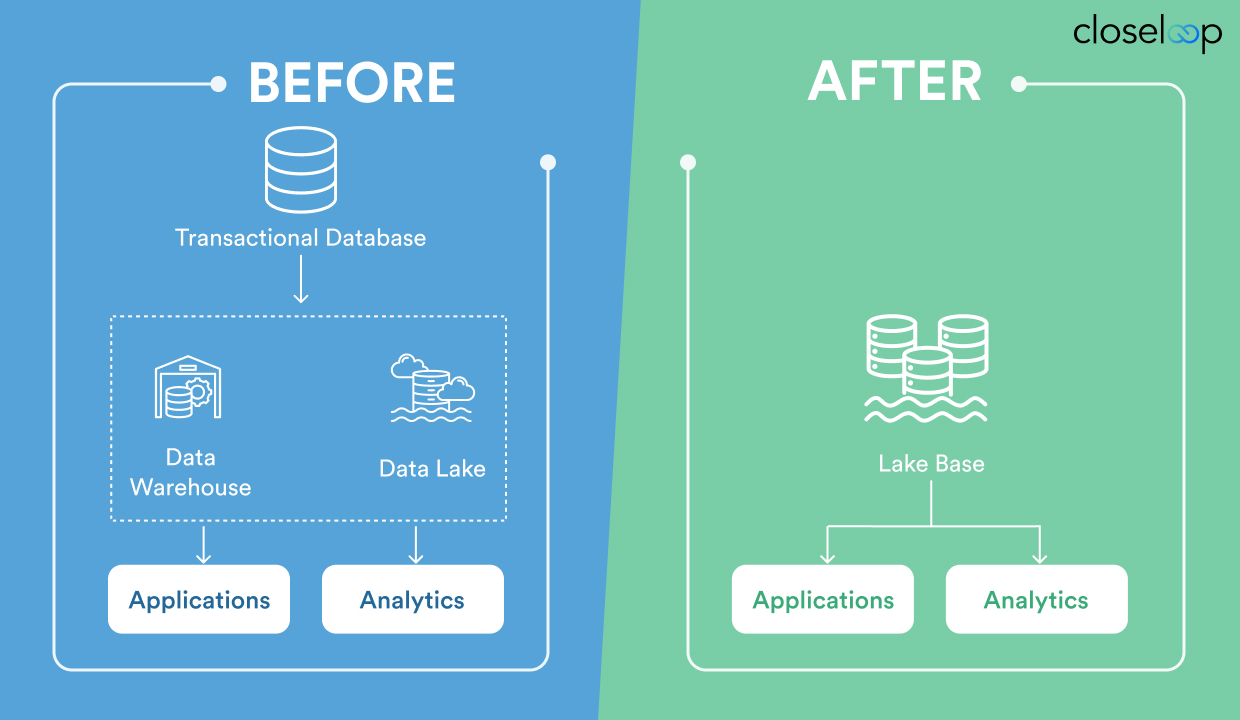
The lakehouse model helped reduce some of that friction by making analytics easier on top of cloud-native storage. But it never fully replaced transactional databases. Until now.
Databricks Lakebase introduces a unified approach. It builds on Delta Lake and the lakehouse foundation, but adds native support for transactional workloads, allowing teams to read, write, update, and query the same data in real time. Unlike traditional systems, Lakebase doesn’t require a separate OLTP database to support operational use cases. You can run inserts, updates, deletes, and even full applications directly on your Delta tables, an example of how Databricks is changing data workloads with a Lakebase unified data platform.
This shift is raising a key question across data engineering and platform teams: Can OLTP and OLAP finally live in the same system, without tradeoffs?
In this blog, we’ll explain what Lakebase is, how Lakebase works under the hood, and why it matters for modern teams managing both data platforms and applications. We’ll compare it to legacy databases and warehouses, explore real-world applications of Lakebase, and unpack how capabilities like database branching and versioning change how teams build, test, and scale.
If your current setup still involves juggling multiple databases to support analytics and operations, it may be time to look at what Databricks Lakebase is doing.
What Is a Lakebase?
A Lakebase is Databricks’ latest extension of the lakehouse architecture that brings transactional workloads and analytics together on the same platform, using Delta Lake as the core foundation. It allows teams to build complete applications, those that need frequent updates, inserts, and deletes, directly on their analytical data.
Unlike traditional databases, Lakebase does not store data in a separate transactional engine. Instead, it treats the data lake itself as the database, enabling real-time operations on open formats with full ACID guarantees (Lakebase architecture explained through the lens of Delta Lake).
Learn more about how data lakes work in our architecture guide.
If you are asking, “What is Lakebase in Databricks?” think of it as a database built on Delta Lake that supports both OLTP and OLAP from the same storage layer, enabling unified analytics with Lakebase as part of daily operations.
Built on the Lakehouse Model
Lakehouse architecture solved a long-standing problem: how to run analytics directly on cloud object storage, without the cost and rigidity of traditional warehouses. It merged the flexibility of data lakes with structured querying and performance tuning of data warehouses using Delta Lake for transactions, schema enforcement, and versioning.
Lakebase pushes that vision further by expanding the workloads that lakehouses can support. Where the lakehouse was built for BI, reporting, and machine learning, Lakebase brings native support for operational workloads like inventory systems, real-time customer updates, and event-driven applications, clarifying Databricks Lakehouse vs Lakebase as analytics-first versus fully unified.
This happens without building a separate OLTP layer. Everything runs on Delta tables, with Databricks managing consistency, latency, and concurrency at scale.
Key Capabilities of Lakebase
Key features include:
-
Real-time writes and queries: Perform inserts, updates, and deletes directly on Delta tables, while supporting concurrent reads for analytics.
-
Low-latency performance: Built-in indexing, caching, and vectorized execution make it responsive enough for operational use cases.
-
Table cloning and database branching: Teams can instantly clone tables or databases for dev/test environments or time travel without duplicating data.
-
Full ACID compliance: Ensures data consistency and reliability across both analytical and transactional operations.
These features allow applications and dashboards to run on the same data, at the same time, without conflict or delay—the core benefits of Lakebase.
No More OLTP vs. OLAP Divide
Traditionally, engineers had to architect for separation. OLTP systems handled writes and transactions. OLAP systems handled queries and analysis. Syncing them meant building pipelines, dealing with delays, and resolving schema mismatches.
Lakebase removes that divide. You can use a single Delta table to power both use cases, real-time updates from applications and analytical queries from dashboards or notebooks, reducing unified data management challenges tied to duplication and ETL.
By treating the data lake as the primary database for all workloads, Lakebase marks a step change in how data engineering with Lakebase simplifies platforms.
The Evolution: From Lakehouse to Lakebase
What Lakehouses Solved
Before lakehouses, organizations had two main options for data: structured, high-performance warehouses for analytics, or flexible data lakes for storing large volumes of raw data. Warehouses were fast but expensive and rigid. Lakes were scalable and cost-effective but difficult to query without significant engineering effort.
The lakehouse architecture emerged to close that gap. Built on open formats like Delta Lake, it offered the flexibility of cloud storage with the performance of a warehouse. Teams could run BI, machine learning, and advanced analytics directly on their data lake without copying data into a separate warehouse system.
With schema enforcement, ACID transactions, and support for concurrent queries, lakehouses allowed organizations to consolidate analytical workloads, reduce ETL pipelines, and simplify their data architecture.
But even with all those benefits, lakehouses were not designed for high-frequency transactional updates. That’s where things still broke down.
|
If you are new to lakehouses, start with our overview of the architecture and its role in AI and analytics. |
What Was Still Missing
The lakehouse model was built for analytics-first use cases. It worked well for dashboards, batch workloads, machine learning training, and exploratory analysis. But for real-time applications, where data needs to be updated frequently and served instantly, it fell short.
Operational systems like inventory updates, order processing, financial entries, or IoT sensor logs often require thousands of small writes per second. These are classic OLTP workloads. And even with Delta Lake’s improvements, most teams still needed to manage a separate transactional database for those use cases.
That meant splitting workloads again: one system for transactions, one for analytics, and pipelines in between.
|
See how common pipeline failures affect costs and performance in our breakdown of real-world data pipeline issues. |
Where Lakebase Fits
Lakebase was introduced to close this remaining gap. It keeps everything that made lakehouses powerful, open formats, unified governance, and Delta Lake, but adds native support for transactional applications.
By integrating OLTP-like performance into the lakehouse, Lakebase allows teams to build full applications directly on top of their analytical storage layer. You can now run frequent inserts and updates on the same Delta tables used by BI tools or machine learning models, without duplicating data or building ETL pipelines. That’s the future of unified data workloads moving from concept to standard practice
This shift redefines the boundary between operational and analytical workloads. Lakebase offers a simpler, unified model: one system, one copy of data, built for both transactions and insights.
Lakebase Architecture Explained
Lakebase may sound like a new type of database, but at its core, it is a smarter way of using the lakehouse you already know, just now with full support for operational use cases. It brings together transactional speed and analytical flexibility using Delta Lake, with new features built for application-level performance.
Let’s break it down.
Delta Lake as the Foundation
Everything in Lakebase runs on Delta Lake, which already powers the Databricks lakehouse. Delta Lake provides the critical foundation: ACID transactions, scalable metadata handling, and support for concurrent reads and writes. That means data remains consistent even as multiple users or services interact with the same table at the same time.
What Lakebase does is optimize Delta Lake further, so that instead of just powering dashboards or ML models, it can also support real-time transactions and frequent data updates like a traditional OLTP database.
Indexing, Caching, and Performance Tuning
To achieve low-latency transactional performance, Lakebase includes built-in indexing and caching mechanisms under the hood. These features reduce read and write times without requiring custom tuning or manual configuration.
The platform uses vectorized execution to speed up query processing and includes intelligent file compaction strategies to manage storage efficiently. This helps keep performance consistent, even as table sizes grow or as thousands of small updates are written throughout the day, an implementation detail that shows how Lakebase works day to day.
Table Clones and Database Branching
One of the most practical features introduced with Lakebase is database branching, supported through Delta Lake’s native table cloning.
Teams can use branching to create instant, zero-copy clones of production databases. These clones can be used for testing, development, debugging, or even backup restoration, without creating a second copy of the data.
The clone remains tightly linked to the original dataset, and any changes in the branch don’t affect production. This enables faster development cycles and safer experimentation, especially when combined with Git-style version control.
Instead of managing dev/test/prod environments manually or exporting test data, engineers can spin up full-featured environments in seconds.
No Need for a Separate Operational Database
Traditionally, developers needed a dedicated transactional database to support app logic and a separate system for analytics. That often meant syncing data between systems using ETL pipelines or real-time replication tools.
Lakebase removes that requirement entirely.
Applications can now interact with Delta tables directly, writing data, updating records, and running queries from the same place. The same data serves both operational and analytical purposes. That alignment drives unified analytics with Lakebase and lowers integration overhead.
How Lakebase Works in Practice
Lakebase stands out not just because of what it enables, but because of how seamlessly it fits into everyday workflows. The same Delta tables used for analytics can now handle high-frequency transactions. This means teams don’t need to build separate systems, reconcile data, or wait on batch pipelines to refresh dashboards.
Real-world applications of Lakebase include:
Real-Time Updates and Analytics on Shared Tables
Lakebase allows applications and analytics tools to operate on the same underlying data without conflict. When an operational system writes to a Delta table, whether it is a customer action, order update, or sensor input, that data is immediately available to notebooks, BI dashboards, or data pipelines. There’s no duplication, delay, or sync job required.
For teams running both applications and analytics on Databricks, this removes a major bottleneck.
Example: Inventory Management in a Retail System
Imagine a retailer tracking inventory across 500 stores. Every point-of-sale transaction updates a Delta table with current stock levels. At the same time, analysts run dashboards to monitor product availability, sales trends, or restocking needs.
With Lakebase, both the application recording the sale and the dashboard pulling availability data operate on the same Delta table. Transactions are fast, consistent, and visible instantly, without any pipeline or duplication.
This use case was previously handled by two systems: a fast OLTP database for operations and a warehouse for reporting. Lakebase eliminates that divide, simplifying infrastructure and reducing latency.
Comparing Lakebase to Traditional Systems
Lakebase is positioned as a unified solution for teams that have historically relied on separate systems for operations and analytics. To understand how it changes the landscape, let’s compare it directly to the systems it aims to replace or consolidate.
Lakebase vs. OLTP Databases
Traditional OLTP databases like Postgres, MySQL, or SQL Server are designed for fast, transactional processing. They work well for applications that need low-latency reads and writes, things like user updates, payments, or inventory changes. However, they are not built for large-scale analytics. Running complex queries on transactional databases can slow performance, affect concurrency, and require additional tuning.
Lakebase matches OLTP systems in its ability to support fast updates, inserts, and deletes but does so on a scalable, open-format data layer. And it does more: the same data can be queried for analytics without moving it to a separate system.
For modern teams, this means fewer architectural tradeoffs. Instead of maintaining a transactional database for apps and a warehouse for analysis, Databricks Lakebase enables both in a single environment.
Lakebase vs. Data Warehouses
Data warehouses are optimized for analytical workloads. They offer high-performance querying, support for complex aggregations, and integration with BI tools. But they are not designed to handle real-time application writes. Loading data into a warehouse usually requires ETL pipelines or batch jobs that introduce delays.
Lakebase offers similar analytical performance, thanks to Delta Lake’s indexing, caching, and file management, but adds the ability to support real-time operational writes on the same data. That’s a significant advantage for use cases where updates and insights need to happen together.
Lakebase vs. Lakehouse Without Transactional Support
A traditional lakehouse architecture supports analytics well but still requires teams to use an external database for transactional workloads. While Delta Lake introduced ACID compliance, those benefits weren’t enough for high-throughput, low-latency application logic.
Lakebase extends the lakehouse by integrating performance enhancements specifically for transactional use cases: low-latency reads and writes, table-level branching, and fine-grained concurrency management.
In short, it removes the last major barrier to full unification.
Summary: Feature-by-Feature Comparison
|
Feature |
Traditional OLTP |
Data Warehouse |
Lakehouse (Standard) |
Lakebase |
|
Real-time writes (OLTP) |
✅ |
❌ |
⚠️ Limited |
✅ |
|
Analytics at scale (OLAP) |
⚠️ Limited |
✅ |
✅ |
✅ |
|
ACID compliance |
✅ |
⚠️ Partial |
✅ |
✅ |
|
Unified data layer |
❌ |
❌ |
✅ |
✅ |
|
Support for branching/versioning |
❌ |
❌ |
⚠️ Limited |
✅ |
|
Open format/cloud storage |
❌ |
⚠️ Varies |
✅ |
✅ |
Lakebase offers a simplified, unified path forward for enterprises tired of stitching systems together. It doesn’t aim to replace all OLTP systems, but for many hybrid workloads, it can replace the entire stack.
Benefits of Lakebase for Modern Data Teams
Simpler Architecture, No ETL
One of the biggest advantages of Lakebase is that it eliminates the need to maintain separate OLTP and OLAP systems. There’s no need to sync data between an operational database and a data warehouse. Everything runs on Delta Lake, with consistent performance across real-time writes and large-scale queries.
This means fewer pipelines, fewer integration points, and fewer failure modes. Teams no longer have to spend time building and maintaining ETL jobs just to make data usable.
Faster Development and Testing
Lakebase supports database branching and table cloning, allowing developers to spin up isolated environments instantly. This accelerates the typical dev → test → prod cycle. Teams can experiment with schema changes, test new features, or debug issues without impacting production data.
Because these clones are built on Delta Lake, they don’t require duplicating entire datasets. That means faster setup and lower storage costs, without compromising on safety or speed.
Cost and Complexity Reduction
Managing two or three different systems to support transactional and analytical workloads comes with hidden costs: licensing, compute, storage, and operational overhead. Lakebase reduces this by enabling teams to work within a single environment.
It also allows organizations to better use their cloud budgets. There’s no need to pay for compute in multiple systems or handle capacity planning across silos.
Easier Collaboration Across Roles
When data scientists, analysts, and developers work on the same data infrastructure, collaboration improves. With shared access to live data, analysts work with fresher insights, developers skip manual extract requests, and data scientists train models on current, consistent tables.
These themes shape Lakebase use cases for enterprises, creating a common workspace where all stakeholders can interact with shared, consistent data, without waiting on refresh cycles or handoffs between teams.
Lakebase Use Cases for the Enterprises
Lakebase is designed to support workloads that demand both operational speed and analytical depth, something traditional systems often split between two stacks. By supporting real-time transactions and analytics on the same data layer, Lakebase enables a wide range of enterprise use cases.
Inventory and Supply Chain Systems
In logistics and retail, inventory data changes constantly. Orders are placed, shipments arrive, and stock is transferred. With Lakebase, these updates can be written directly to Delta tables, while real-time dashboards pull from the same tables to track availability, delays, or restock needs.
Example: A nationwide retail chain can track item availability in real time, updating store-level stock every few seconds while analytics teams monitor trends across regions. There’s no batch lag, no need for a second warehouse.
Customer Order Processing with Embedded Analytics
E-commerce platforms and fulfillment providers rely on high-throughput order systems. At the same time, customer success, operations, and finance teams need visibility into those orders as they are processed.
Lakebase supports this by allowing order events: placement, payment, and fulfillment, to be recorded in real time, with live analytics layered directly on top. This enables deeper insight into order status, exceptions, and fulfillment rates without exporting data to a separate warehouse.
Example: A direct-to-consumer brand can track order completion rates in real time while simultaneously flagging delayed shipments for customer service outreach, all from the same data layer.
Real-Time Personalization at Scale
Personalization engines depend on fast data like clickstreams, cart activity, and browsing behavior. Lakebase can record those user interactions in milliseconds and immediately make them available for targeting logic or model-driven recommendations.
Example: A travel app can log recent searches and bookings in real time, then use those signals to update offers or suggestions for each user, without syncing to another system.
Financial Systems and Unified Ledgers
Financial teams need precision, consistency, and speed. Lakebase supports transaction logging with full ACID compliance, while enabling real-time rollups, forecasting, and auditing.
Example: A fintech firm can write journal entries and transaction events directly into Delta tables and feed live dashboards for auditors, controllers, and decision-makers, no separate system required.
Lakebase opens the door for more unified, responsive enterprise systems where operations and insights are always aligned.
Limitations: Where Lakebase May Not Fit
While Lakebase offers a strong case for unifying operational and analytical workloads, it’s still early in its evolution. Like any new capability, it has boundaries that teams need to understand before planning large-scale adoption.
Still Maturing
Lakebase is built on proven components: Delta Lake, Databricks’ compute engine, and the lakehouse foundation, but its transactional features are still maturing. While the system handles inserts, updates, and deletes well, advanced tuning may be needed to match the performance of deeply optimized OLTP databases in high-throughput scenarios. Teams expecting sub-millisecond latencies or very high concurrency may still need purpose-built transactional engines.
Features like database branching and zero-copy clones are powerful, but managing unified data management challenges at scale will require careful governance, especially in production environments.
When OLTP Systems Still Make Sense
Lakebase is not a one-size-fits-all replacement for all transactional systems. For businesses running mature applications tied to relational databases like Postgres or SQL Server, with deeply embedded stored procedures, proprietary extensions, or ERP systems, it may not be practical or cost-effective to re-architect in the short term.
In these cases, traditional OLTP databases will continue to play a role, especially when transaction volume is high but analytical complexity is low.
Skills, Tooling, and Mindset
Lakebase is built on Delta Lake and requires a good understanding of how data lakes work: file-based storage, partitioning strategies, schema evolution, and versioning. Teams that are new to Databricks may face a learning curve in building and maintaining transactional apps in this environment.
Tooling is also evolving. While SQL support is strong, some integrations and developer workflows are still catching up compared to long-established relational databases.
In short, Lakebase is a strategic choice. For teams looking to simplify data infrastructure and move toward unified architectures, it offers clear benefits. But like any platform shift, it requires planning, alignment, and the right internal capabilities to succeed.
Getting Started with Lakebase on Databricks
For teams already working on Databricks, adopting Lakebase doesn’t require a separate system or platform. It is available natively and supports all three major cloud providers: Azure, AWS, and Google Cloud Platform. That makes it easy to integrate into existing data lakehouse environments without needing to migrate infrastructure or replatform workloads.
Works Seamlessly with Unity Catalog and Delta Sharing
Lakebase is designed to work with Unity Catalog, which provides unified governance, fine-grained access control, and lineage tracking across all assets. If you already manage your Delta tables with Unity Catalog, Lakebase features, including transactional writes and database branching, can be layered on without additional setup.
It also supports Delta Sharing, which means Lakebase-backed tables can be securely shared across teams, business units, or external partners in open format, without moving data or duplicating access layers.
Enabling Lakebase Capabilities
There’s no separate Lakebase product to install or configure. If you’re using Databricks with Delta Lake and Unity Catalog, many of the features like concurrent reads/writes, ACID transactions, and real-time updates are already available by default.
To test Databricks Lakebase capabilities, it is recommended to:
-
Create a Delta table with a primary key structure
-
Run concurrent INSERT, UPDATE, or DELETE operations
-
Query the same table in real time using SQL or notebooks
-
Observe low-latency performance and isolation
You can begin with a small operational dataset, such as inventory or order tracking, to see how transactional updates behave alongside live queries, an easy onramp to the future of data platforms with Lakebase.
How to Use Database Branching
One of the standout features in Lakebase is database branching, which allows developers to clone a database for testing, debugging, or development, without copying data.
To create a branch:
-
Use the CLONE command on a Unity Catalog–enabled database or table
-
Begin working on the branch as a full, isolated environment
-
Apply changes or run tests without affecting production
Full documentation is available on Microsoft Learn for Databricks with detailed steps and examples.
For organizations building transactional applications or modernizing legacy systems, Lakebase offers a fast, integrated way to test and scale without leaving the Databricks ecosystem.
Closeloop’s Take: Why This Matters for Enterprise Data Architecture
For years, businesses have struggled with fragmented stacks: transactional databases built for speed, warehouses built for insight, and complex pipelines holding it all together. Lakebase removes that divide by allowing both application logic and analytics to operate on a shared, governed data layer.
This unified approach simplifies architecture and accelerates time to value. But it also requires a different way of thinking about system design, data modeling, and operational readiness.
That’s where we come in.
At Closeloop, we work with enterprises across industries to evaluate whether Lakebase fits their goals, workloads, and teams. From assessing whether Lakebase can replace legacy OLTP systems to designing hybrid models that balance performance and cost, our data engineering services blend both architectural expertise and hands-on Databricks consulting experience, so Lakebase unified data platform decisions translate into measurable value.
We support:
-
Strategic planning for Lakebase adoption across cloud environments
-
Migration of existing workloads to Delta Lake with transactional support
-
Implementation of Unity Catalog, governance policies, and secure data sharing
-
Custom platform design with application-aware branching and real-time analytics
For organizations modernizing ERP, CRM, or supply chain systems, Lakebase offers a clean path forward. But the real value comes when technology aligns with real business outcomes: simpler systems, faster decisions, and more reliable data.
Final Thoughts: Is Lakebase the Future of Unified Data Workloads?
The idea of a single engine powering both transactions and analytics has been discussed for years, but until recently, it was more aspiration than reality. With Lakebase, Databricks has delivered a working model that changes how enterprise data teams can design, build, and run modern systems.
This shift matters. Teams no longer need to choose between real-time updates and large-scale queries, or maintain complex sync pipelines across OLTP and OLAP environments. With Databricks Lakebase, operations and insights live in the same place, running on Delta Lake, governed by Unity Catalog, and ready for both high-frequency updates and deep analytical workloads.
For organizations that have outgrown siloed systems or are managing sprawl across cloud services, Lakebase offers a path toward architectural simplicity, the future of unified data workloads. It doesn’t aim to replace every OLTP system today, but it can replace many of the duplicate workflows and fragile pipelines that slow down teams and inflate costs.
Lakebase is most valuable when adopted with intent. It requires thoughtful planning, a clear understanding of Delta Lake’s strengths, and alignment across application and analytics teams. But when implemented correctly, it unlocks a more streamlined, responsive, and collaborative data environment.
At Closeloop, we view Lakebase as a strategic tool in the enterprise modernization toolkit. Whether you are optimizing supply chain systems, enabling real-time customer analytics, or building a new operational platform, Lakebase can reduce complexity and accelerate execution.
Curious if Lakebase fits your architecture? Talk to our certified Databricks consultants for a 1:1 review.
Author

Assim Gupta

CEO
Assim Gupta is the CEO and Founder of Closeloop, a cutting-edge software development firm that brings bold ideas to life. Assim is a strategic thinker who always asks “WHY are we doing this?” before rolling up his sleeves and digging in. He is data-driven and highly analytical, yet his passion is working with teams to build unexpected, creative solutions that catapult companies forward.
Stay abreast of what's trending in the world of technology
Cost Breakdown to Build a Custom Logistics Software: Complete Guide
Global logistics is transforming faster than ever. Real-time visibility, automation, and AI...

Logistics Software Development Guide: Types, Features, Industry Solutions & Benefits
The logistics and transportation industry is evolving faster than ever. It’s no longer...

From Hurdle to Success: Conquering the Top 5 Cloud Adoption Challenges
Cloud adoption continues to accelerate across enterprises, yet significant barriers persist....

Gen AI for HR: Scaling Impact and Redefining the Workplace
The human resources landscape stands at a critical inflection point. Generative AI in HR has...

