Data pipelines form the backbone of mission-critical operations across finance, healthcare, manufacturing, and regulatory sectors. In these high-stakes environments, a single pipeline failure can trigger cascading business disruptions, regulatory violations, and reputational damage worth millions. Bad data costs businesses an average of $15 million annually, according to Gartner's Data Quality Market Survey. This backdrop is why building robust data pipelines and applying codified data pipeline best practices is now a board-level priority.
The stakes have never been higher. 85% of organizations are affected by data loss, with costs reaching $7,900 per minute. The average global breach cost has reached USD 4.88 million, with financial industry enterprises facing even higher costs. These environments demand data pipelines for mission-critical environments that not only move data efficiently but also guarantee reliability, compliance, and real-time access under extreme operational pressure, an arena tailor-made for robust data engineering pipelines.
Defining High-Stakes Environments
High-stakes environments operate under unique constraints that amplify the consequences of data pipeline failures. These sectors share common characteristics that distinguish them from standard enterprise applications. Understanding these distinctions is crucial when deciding how to build data pipelines for high-stakes environments and planning for the future of enterprise data pipelines.
Characteristics of High-Stakes Operations
Mission-critical operations run on data pipelines that cannot afford downtime. Financial trading systems process millions of transactions per second, where millisecond delays translate to significant losses. Healthcare systems rely on real-time data pipelines for critical workloads to support life-saving decisions. Regulatory environments demand perfect audit trails for compliance verification, placing data pipeline reliability and performance at the center of design choices.
These environments typically feature large-scale, distributed architectures spanning multiple geographic regions. They operate under strict regulatory scrutiny with zero tolerance for data inconsistencies. The systems must maintain operational continuity while processing massive data volumes with microsecond latency requirements, underscoring the benefits of robust data pipelines in risk reduction and compliance..
Failure Scenarios and Impact Assessment
Pipeline failures in high-stakes environments create cascading effects across multiple business functions. A trading platform's data lag can trigger incorrect algorithmic decisions, resulting in substantial financial losses. Healthcare data corruption can compromise patient safety protocols, leading to regulatory sanctions and legal liability. These are classic high-stakes data pipeline challenges where design decisions determine resilience.
|
Environment |
Common Failure Points |
Business Impact |
Recovery Time |
|
Financial Trading |
Real-time price feeds, market data synchronization |
$1M-$50M per minute |
<30 seconds |
|
Healthcare Systems |
Patient record updates, medication tracking |
Regulatory fines, patient safety risks |
<5 minutes |
|
Manufacturing IoT |
Sensor data streams, quality control metrics |
Production line shutdowns, safety violations |
<2 minutes |
|
Regulatory Reporting |
Compliance data aggregation, audit trails |
Legal penalties, license suspension |
<24 hours |
The ramifications extend beyond immediate operational disruption. 93% of businesses with extended data loss face bankruptcy. Reputational damage compounds financial losses, creating long-term market position erosion. Legal exposure from regulatory violations can result in class-action lawsuits and criminal liability for executive leadership, preventable with optimizing data pipelines for resilience from the outset.
Core Principles for Robust Data Pipeline Design
Robust pipeline architecture requires fundamental design principles that prioritize reliability over convenience. These principles form the foundation for systems that can withstand operational stress while maintaining data integrity, essential when crafting scalable data pipelines for enterprises. Each principle addresses specific failure modes common in high-stakes environments.
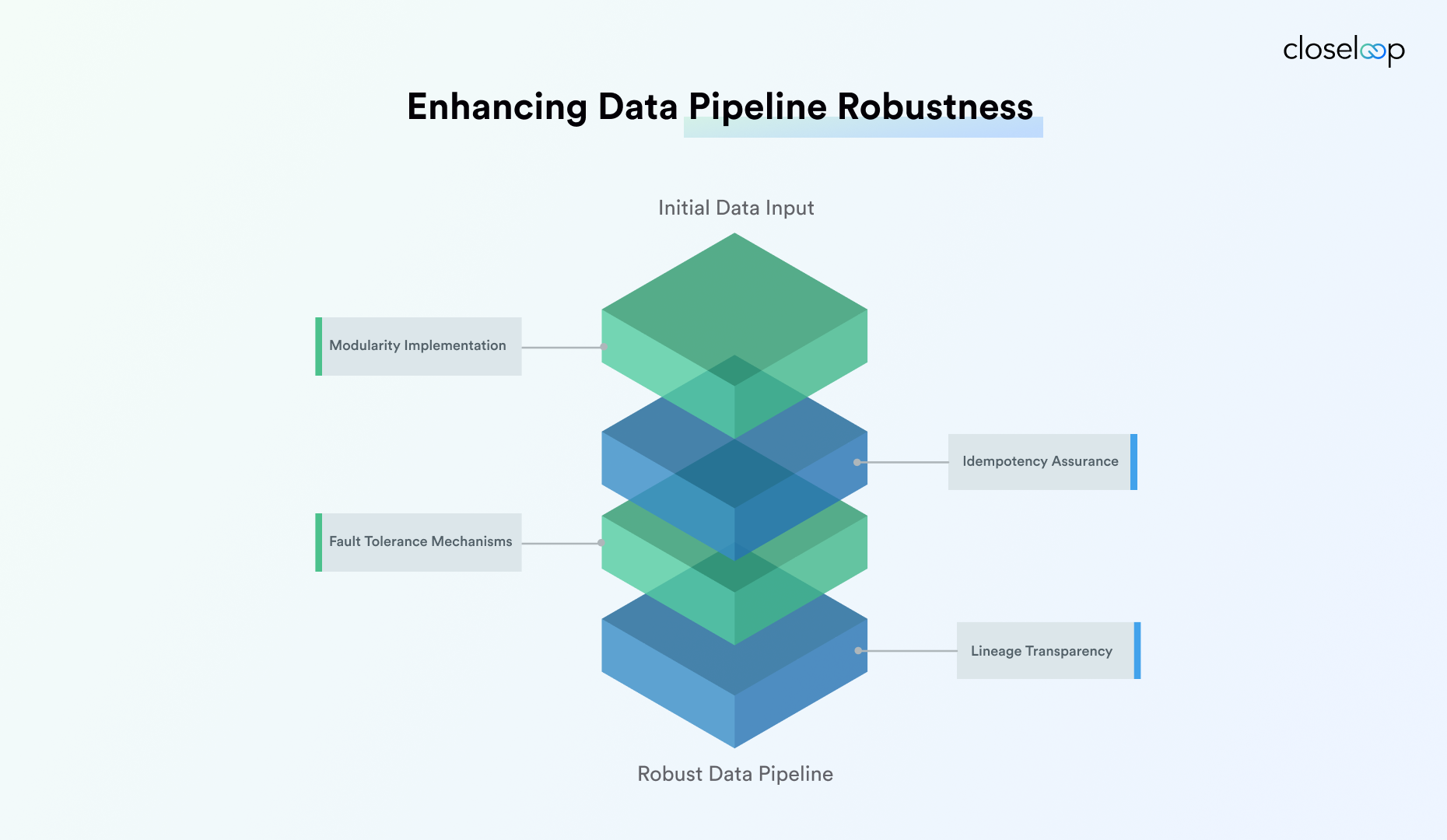
Modularity and Composability
Independent pipeline modules enhance system resilience by isolating failure points and enabling targeted recovery strategies. Each module operates as a self-contained unit with defined input/output contracts, allowing for independent scaling and maintenance. This approach prevents single points of failure from cascading across the entire pipeline infrastructure and is a cornerstone of data engineering for high-stakes systems.
Modular design enables rapid component replacement without system-wide disruption. Teams can upgrade individual modules while maintaining overall system stability. The composable architecture supports flexible pipeline configurations that adapt to changing business requirements without complete system redesigns.
Idempotency and Fault Tolerance
Idempotent operations ensure safe retries without data corruption or duplication. Every pipeline stage must produce identical results regardless of execution frequency. This principle becomes critical during error recovery scenarios where partial executions require careful state management.
Fault tolerance mechanisms include circuit breakers that prevent cascade failures, graceful degradation protocols that maintain core functionality during component outages, and automated rollback procedures that restore known-good states. These systems anticipate failure modes and implement predetermined recovery strategies to protect data pipeline reliability and performance.
|
Fault Tolerance Strategy |
Implementation |
Recovery Time |
Data Integrity |
|
Circuit Breakers |
API gateway patterns |
Immediate |
Preserved |
|
Graceful Degradation |
Backup data sources |
<1 minute |
Reduced accuracy |
|
Automated Rollback |
Version-controlled pipelines |
<5 minutes |
Fully restored |
|
Hot Standby Systems |
Real-time replication |
<30 seconds |
Complete |
Lineage Transparency and Traceability
End-to-end data lineage tracking enables rapid root cause analysis during incidents. Every data transformation must maintain metadata linking outputs to source inputs, processing timestamps, and transformation logic versions. This transparency supports both operational troubleshooting and regulatory compliance requirements, key to secure data pipelines for enterprises that must prove provenance on demand.
Comprehensive lineage systems capture data provenance across multiple pipeline stages, enabling audit teams to verify data accuracy and regulatory compliance. The tracking includes transformation rules, data quality validations, and user access patterns that support forensic analysis during security incidents.
ALSO READ: Top Data Pipeline Challenges And How Enterprise Teams Fix Them
Layered Validation and Quality Assurance
Data quality assurance requires multiple validation layers that catch errors at different pipeline stages. Each layer serves specific purposes while contributing to overall system reliability, one of the core data pipeline best practices for mission-critical pipelines. The layered approach prevents error propagation while maintaining processing efficiency through early detection mechanisms.
Multi-Stage Validation Techniques
Ingestion-level validation verifies data schema compliance, freshness thresholds, and source authenticity before pipeline entry. These checks prevent corrupted or stale data from entering downstream processes. Schema validation ensures data type consistency while freshness checks detect delayed or missing data sources.
Transformation-level validation enforces business rules and statistical profiling standards during data processing. Business logic validation confirms that transformed data meets domain-specific requirements. Statistical profiling detects anomalies in data distributions that might indicate upstream system issues or data corruption.
Pre-production validation includes comprehensive acceptance testing and rollback protocols before data reaches production systems. This final checkpoint verifies end-to-end pipeline functionality while maintaining emergency rollback capabilities for rapid incident response.
Autonomous Data Quality Rules
Machine learning-powered quality rules adapt dynamically to changing data patterns without manual intervention, strengthening robust data pipelines with Databricks. These systems learn normal data behavior patterns and automatically adjust validation thresholds based on historical trends. Autonomous rules reduce false positive alerts while improving detection accuracy for genuine data quality issues.
|
Validation Layer |
Primary Function |
Error Detection Rate |
Processing Overhead |
|
Ingestion |
Schema & freshness |
85% |
2-5% |
|
Transformation |
Business rules |
78% |
8-12% |
|
Pre-production |
End-to-end testing |
92% |
15-20% |
|
Autonomous ML |
Pattern recognition |
89% |
3-7% |
Dynamic rule generation leverages clustering algorithms to identify data quality patterns across multiple dimensions. The system automatically creates new validation rules based on detected anomalies and refines existing rules based on feedback loops from downstream processes.
Modern Pipeline Architectures for Hybrid Systems
Contemporary data architectures span multiple deployment models, requiring sophisticated orchestration capabilities. Hybrid systems bridge cloud-native services with on-premises legacy systems while maintaining consistent performance and security standards. This is where scalable data pipelines on Databricks and similar platforms shine for cross-environment orchestration.
Orchestrating Multi-Environment Operations
Cloud, on-premises, and edge environments each present unique operational challenges that require specialized orchestration strategies. Cloud environments offer elastic scaling but introduce network latency and vendor dependency risks. On-premises systems provide control and compliance but limit scalability and require significant infrastructure investment.
Edge computing adds real-time processing capabilities for IoT and mobile applications but creates data synchronization challenges across distributed nodes. Effective orchestration balances these trade-offs while maintaining consistent data quality and security standards across all deployment targets, vital for data pipelines for mission-critical environments at global scale.
Hybrid Pipeline Strategies
Legacy system integration requires careful bridge architectures that minimize disruption while enabling gradual modernization. These strategies include API gateway patterns that abstract legacy interfaces, data virtualization layers that provide unified access to distributed sources, and event-driven architectures that decouple systems through asynchronous messaging.
Modern platforms support seamless data movement between heterogeneous systems through standardized protocols and transformation engines. The bridge architectures include change data capture mechanisms that synchronize legacy databases with modern analytics platforms in real-time.
|
Integration Pattern |
Use Case |
Complexity |
Risk Level |
|
API Gateway |
Legacy system access |
Medium |
Low |
|
Data Virtualization |
Multi-source queries |
High |
Medium |
|
Event-Driven Sync |
Real-time updates |
High |
Low |
|
Direct Database Replication |
High-volume sync |
Low |
High |
Synchronization Mechanisms
Synchronous data synchronization provides immediate consistency guarantees but introduces latency and availability dependencies. This approach suits transaction processing systems where data consistency outweighs performance considerations. Synchronous patterns include distributed transactions and two-phase commit protocols.
Asynchronous synchronization offers better performance and availability through eventual consistency models, critical to real-time data pipelines for critical workloads. These mechanisms include message queues, event streaming platforms, and change data capture systems that maintain data consistency without blocking primary operations.
ALSO READ: ETL vs ELT: Choosing the Right Data Pipeline Model
Advanced Data Trust and Integrity
Data trust represents a fundamental requirement for high-stakes environments where decisions based on incorrect information can trigger catastrophic outcomes. Building trust requires comprehensive validation, monitoring, and governance frameworks, tenets of secure data pipelines for enterprises, that operate continuously throughout the pipeline lifecycle. These systems must balance automation with human oversight to maintain operational efficiency.
Data Trust as Built-in Feature
Automated profiling systems analyze data characteristics at ingestion points, establishing baseline patterns for ongoing validation. These profiles include statistical distributions, null value frequencies, and relationship constraints that define normal data behavior. The profiling engines update continuously as data patterns evolve.
Validation engines apply business rules, statistical checks, and machine learning models to detect anomalies in real-time. Cleansing processes automatically correct common data quality issues while flagging complex problems for human review, bringing the benefits of robust data pipelines into daily operations. The validation includes cross-reference checks against authoritative data sources.
Continuous Monitoring and Trust Certification
Circuit-breaker patterns prevent degraded data from propagating through downstream systems when quality thresholds are breached. These mechanisms automatically isolate problematic data sources while maintaining partial system functionality through alternative data paths. Trust score certifications provide quantitative measures of data reliability.
Automated anomaly detection leverages unsupervised learning algorithms to identify unusual patterns that might indicate data corruption, security breaches, or system malfunctions. The detection systems operate continuously on streaming data with millisecond response times for critical alerts to uphold secure data pipelines Databricks deployments and beyond.
|
Trust Mechanism |
Detection Method |
Response Time |
Accuracy Rate |
|
Statistical Profiling |
Baseline deviation |
<100ms |
87% |
|
ML Anomaly Detection |
Unsupervised clustering |
<50ms |
92% |
|
Business Rule Validation |
Rule engine |
<10ms |
95% |
|
Cross-reference Checks |
External API calls |
<500ms |
98% |
Governance Frameworks for Mission-Critical Use
Data governance in high-stakes environments requires automated policy enforcement combined with comprehensive audit capabilities. Governance frameworks include role-based access controls, data classification schemes, and retention policies that operate transparently within pipeline operations.
Automated compliance monitoring verifies adherence to regulatory requirements including GDPR, HIPAA, SOX, and industry-specific standards, everything needed to keep data pipelines for mission-critical environments compliant and trustworthy. The monitoring includes data lineage tracking, access logging, and retention policy enforcement that support regulatory audits and forensic investigations.
Scalability and Adaptability Innovations
Modern pipeline architectures must scale elastically while maintaining consistent performance characteristics. This is a natural fit for robust data pipelines with Databricks and modern lakehouse tooling. Innovation focuses on eliminating traditional bottlenecks through architectural patterns that support massive concurrency and real-time processing. These approaches enable organizations to handle exponential data growth without proportional infrastructure investment.
Zero-ETL and Reverse ETL Architectures
Zero-ETL architectures eliminate traditional extract-transform-load bottlenecks by performing transformations at query time rather than during data movement. This approach reduces pipeline complexity while enabling real-time analytics on raw data sources. Query engines optimize transformations dynamically based on usage patterns.
Reverse ETL patterns enable operational systems to consume processed analytics data without complex integration projects, delivering benefits of robust data pipelines without excessive complexity These architectures support closed-loop operations where insights from analytics systems automatically trigger operational actions. The patterns include real-time scoring, automated decision-making, and dynamic configuration updates.
Change Data Capture for Agile Operations
CDC systems capture incremental changes from source databases in real-time, eliminating the need for full data reloads and reducing processing latency. These mechanisms support both transaction log parsing and trigger-based capture methods, depending on source system capabilities.
Incremental synchronization reduces network bandwidth requirements and processing overhead while maintaining data freshness. The systems include conflict resolution algorithms for handling concurrent updates and ordering guarantees for maintaining transaction consistency.
|
CDC Implementation |
Latency |
Overhead |
Complexity |
|
Transaction Log Parsing |
<100ms |
5-10% |
High |
|
Trigger-Based Capture |
<1s |
15-25% |
Medium |
|
Timestamp-Based Polling |
1-5min |
10-20% |
Low |
|
Event-Driven Push |
<50ms |
3-8% |
High |
Modular Pipeline Templates
Reusable pipeline templates accelerate deployment while ensuring consistent quality standards across multiple implementations. Templates include pre-configured validation rules, monitoring configurations, and security policies, accelerating scalable data pipelines for enterprises while reducing human error.
Template libraries support rapid onboarding of new data sources through standardized connection patterns and transformation logic. The modular approach enables teams to compose complex pipelines from proven components while maintaining architectural consistency.
Operational Excellence for Data Pipelines
Operational excellence requires comprehensive monitoring, automation, and
optimization strategies so data pipeline reliability and performance hold
under peak loads. These practices focus on proactive issue detection and
automated remediation to minimize manual intervention requirements. Excellence
emerges from consistent application of proven operational patterns.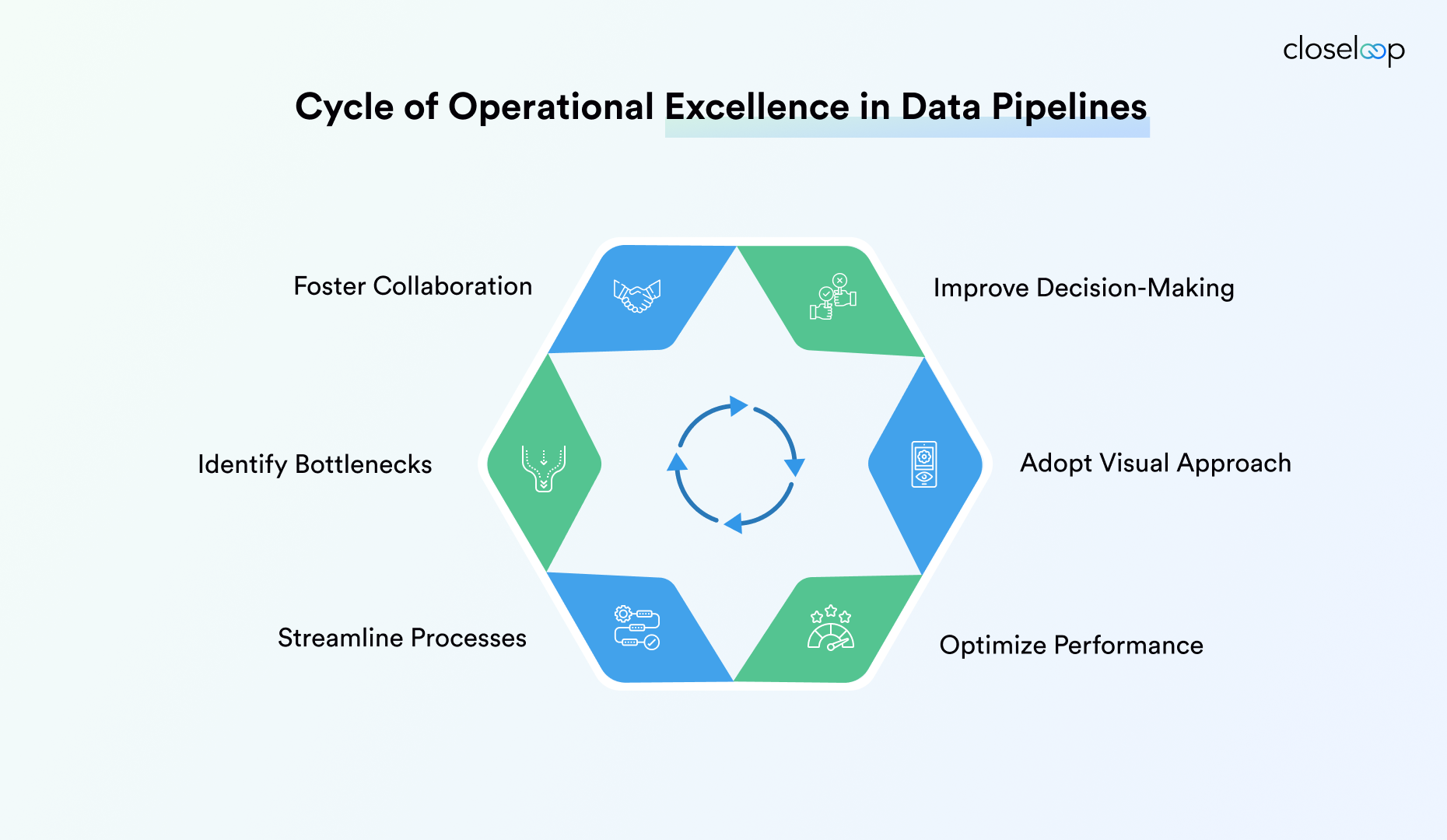
Proactive Monitoring and Observability
Real-time visibility into pipeline health includes latency tracking, throughput monitoring, and error rate analysis for real-time data pipelines for critical workloads. Monitoring systems provide detailed metrics on data flow patterns, processing bottlenecks, and resource utilization that enable predictive maintenance strategies.
Observability platforms correlate metrics across multiple system layers to identify root causes of performance degradation. The systems include distributed tracing capabilities that track individual data records through complex pipeline networks. Alert systems prioritize notifications based on business impact rather than technical severity.
Automation in Data Operations
Streamlined data ingestion eliminates manual intervention through intelligent source detection, automatic schema inference, and dynamic scaling based on data volume patterns. Automated transformation engines apply business rules consistently while adapting to changing data formats and structures, a force multiplier in robust data engineering pipelines.
Error management automation includes intelligent retry strategies, automatic data quarantine for quality violations, and escalation procedures that engage human operators only when automated recovery fails. The automation reduces operational overhead while improving response times for critical issues.
|
Automation Area |
Manual Effort Reduction |
Error Rate Improvement |
Implementation Cost |
|
Data Ingestion |
75-85% |
60% reduction |
Medium |
|
Transformation Logic |
60-70% |
45% reduction |
High |
|
Error Handling |
80-90% |
70% reduction |
Low |
|
Resource Scaling |
90-95% |
85% reduction |
Medium |
Cost and Resource Optimization
Resource optimization strategies balance cost efficiency with performance requirements through dynamic scaling, intelligent caching, and workload scheduling, disciplines that keep scalable data pipelines on Databricks and other platforms both fast and cost-efficient. These approaches prevent over-provisioning while maintaining performance guarantees during peak usage periods.
Cost optimization includes data lifecycle management policies that automatically migrate aging data to lower-cost storage tiers while maintaining access patterns. Compression and deduplication techniques reduce storage requirements without impacting query performance.
ALSO READ: This Is How AI Is Quietly Rewriting Data Engineering Landscape
Security, Compliance, and Risk Mitigation
Security frameworks for high-stakes data pipelines must address data in motion, at rest, and during processing while maintaining operational efficiency, which underpins secure data pipelines for enterprises. Compliance requirements add layers of complexity that require automated verification and audit trail generation. Risk mitigation strategies anticipate threat vectors specific to pipeline architectures.
Secure Data Movement
Encryption protocols protect data during transit between pipeline components using industry-standard algorithms and key management systems. End-to-end encryption ensures data remains protected even when passing through untrusted network segments or cloud engineering provider infrastructure.
Tokenization strategies replace sensitive data elements with non-sensitive equivalents while preserving analytical value. Access controls implement zero-trust principles where every component must authenticate and authorize data access requests regardless of network location.
Automated Compliance and Audit Trails
Compliance automation verifies adherence to regulatory standards, including data retention policies, access logging requirements, and privacy protection mandates, key for data pipelines for mission-critical environments under regulator scrutiny. Several data quality issues are discovered only after they've already affected business decisions. Automated systems prevent this delayed detection through continuous compliance monitoring.
Audit trail generation captures comprehensive metadata about data access, transformation logic, and user activities that support regulatory investigations. The trails include immutable timestamps, user identification, and change documentation that satisfy legal discovery requirements.
|
Compliance Standard |
Automation Level |
Audit Requirements |
Implementation Effort |
|
GDPR |
85% automated |
Data lineage, consent tracking |
High |
|
HIPAA |
90% automated |
Access logs, encryption verification |
Medium |
|
SOX |
95% automated |
Financial data integrity, controls testing |
High |
|
PCI-DSS |
80% automated |
Payment data security, vulnerability scanning |
Medium |
Rapid Breach Response
Incident response procedures include automated threat detection, immediate containment protocols, and forensic data collection that supports investigation activities, vital for data pipelines for mission-critical environments. Response systems integrate with security information and event management platforms for coordinated incident handling.
Data anomaly response includes automatic quarantine mechanisms that isolate suspicious data while maintaining operational continuity through alternative data sources. The systems include notification procedures that alert stakeholders within minutes of anomaly detection.
Future-Forward Concepts: AI-Driven and Autonomous Pipelines
Artificial intelligence integration transforms data pipelines from reactive systems into predictive, self-optimizing platforms, the future of enterprise data pipelines. These autonomous capabilities reduce operational overhead while improving reliability through intelligent decision-making. AI predictions anticipate issues before they impact business operations.
Self-Healing Architectures
Self-healing systems automatically detect and resolve common pipeline issues without human intervention. These capabilities include automatic retry strategies for transient failures, dynamic resource allocation for performance optimization, and intelligent routing around failed components, optimizing data pipelines for resilience without human intervention.
Predictive maintenance algorithms analyze system performance patterns to identify components approaching failure thresholds. The systems schedule maintenance activities during optimal windows while preparing backup resources to maintain continuity.
Autonomous Troubleshooting and Optimization
Machine learning models and AI integration analyze pipeline performance data to identify optimization opportunities and recommend configuration changes. These systems continuously tune processing parameters, resource allocation, and routing strategies based on observed performance patterns.
Autonomous troubleshooting includes root cause analysis capabilities that correlate symptoms across multiple system components to identify underlying issues, raising the ceiling on data pipeline reliability and performance. The systems provide detailed diagnostic information and recommended remediation steps to operations teams.
|
AI Capability |
Automation Level |
Performance Impact |
Implementation Complexity |
|
Predictive Maintenance |
70% automated |
25% improvement |
High |
|
Dynamic Optimization |
85% automated |
35% improvement |
Medium |
|
Anomaly Detection |
90% automated |
60% faster detection |
Medium |
|
Resource Scaling |
95% automated |
40% cost reduction |
Low |
Democratization and Self-Service Capabilities
Low-code pipeline authoring tools enable business users to create and modify data flows without extensive technical expertise, helping teams standardize how to build data pipelines for high-stakes environments without bottlenecks. These platforms include drag-and-drop interfaces, pre-built connectors, and automated validation that ensure pipeline quality while accelerating development cycles.
Self-service monitoring dashboards provide business users with real-time visibility into pipeline performance and data quality metrics. The interfaces include customizable alerts and automated reports that keep stakeholders informed without requiring technical intervention.
ALSO READ: Future of Artificial Intelligence
Closeloop: Transforming Data Pipeline Engineering
Closeloop specializes in building robust data pipelines that avoid vendor lock-in while maintaining architectural flexibility. The company focuses on practical implementation strategies that address real-world operational challenges in high-stakes environments. Our work spans robust data pipelines with Databricks, secure data pipelines Databricks, and hybrid deployments, always with enterprise governance. Our approach emphasizes strategic consulting combined with deep expertise in AI agents in data engineering.
Platform-Agnostic Design Philosophy
Closeloop's platform-agnostic designs support cloud, on-premises, and hybrid deployments without architectural compromises. This flexibility in platform engineering enables organizations to optimize deployment strategies based on regulatory requirements, cost considerations, and performance characteristics rather than technology constraints.
The designs include abstraction layers that isolate business logic from infrastructure specifics, enabling seamless migration between platforms as requirements evolve. Standardized APIs ensure consistent functionality across different deployment environments.
Embedded Security and Compliance
Security and compliance capabilities are integrated as standard pipeline layers rather than bolt-on solutions. This embedded approach ensures consistent policy enforcement while reducing implementation complexity and operational overhead. To align with executive priorities, this architecture also advances AI security for business leaders by embedding guardrails, auditability, and governance into each stage of the development and deployment lifecycle
Monitoring systems provide real-time visibility into security posture and compliance status through automated dashboards and alert systems. The platforms include comprehensive logging and audit trail generation that support regulatory requirements and forensic investigations.
Collaborative Implementation Approach
Closeloop's collaborative workshops engage both technical and non-technical stakeholders to ensure comprehensive requirement gathering and solution design. These sessions include hands-on training that ensures your teams can run scalable data pipelines on Databricks or any stack independently.
Tailored data engineering services address organization-specific challenges through custom architecture design, implementation guidance, and knowledge transfer. The approach ensures sustainable solutions that grow with organizational capabilities rather than creating external dependencies.
Conclusion
The future of robust data engineering pipelines lies in architectural agility that adapts to changing requirements while maintaining unwavering reliability standards. 50% of organizations report that project teams spend over 61% of their time on data integration and pipeline development. Embedded trust mechanisms and automation reduce this overhead while improving operational outcomes.
Investing in composable, self-monitoring, and resilient data infrastructures has become essential for organizations operating in high-stakes domains. The convergence of AI-driven optimization, autonomous operations, and embedded security creates opportunities for unprecedented operational efficiency.
Organizations that embrace data pipeline best practices and adopt these advanced pipeline architectures will gain competitive advantages through faster decision-making, reduced operational risk, and improved regulatory compliance, clear benefits of robust data pipelines that compound over time. The technology foundation exists today to transform data pipeline operations from reactive maintenance to proactive value creation that directly supports business objectives. Talk to our certified experts today.
Author

Saurabh Sharma

VP of Engineering
VP of Engineering at Closeloop, a seasoned technology guru and a rational individual, who we call the captain of the Closeloop team. He writes about technology, software tools, trends, and everything in between. He is brilliant at the coding game and a go-to person for software strategy and development. He is proactive, analytical, and responsible. Besides accomplishing his duties, you can find him conversing with people, sharing ideas, and solving puzzles.
Stay abreast of what's trending in the world of technology
Cost Breakdown to Build a Custom Logistics Software: Complete Guide
Global logistics is transforming faster than ever. Real-time visibility, automation, and AI...

Logistics Software Development Guide: Types, Features, Industry Solutions & Benefits
The logistics and transportation industry is evolving faster than ever. It’s no longer...

From Hurdle to Success: Conquering the Top 5 Cloud Adoption Challenges
Cloud adoption continues to accelerate across enterprises, yet significant barriers persist....

Gen AI for HR: Scaling Impact and Redefining the Workplace
The human resources landscape stands at a critical inflection point. Generative AI in HR has...

