The data engineering landscape is experiencing unprecedented transformation as organizations grapple with exponentially growing data volumes—projected to reach 175 zettabytes globally by 2025. This is accelerating interest in AI agents for data engineering, AI-powered data engineering, and intelligent automation in data engineering that reduces toil and improves reliability. AI agents represent software entities capable of autonomous decision-making, pattern recognition, and adaptive learning that promise to revolutionize how we build, maintain, and optimize data infrastructure with data engineering automation with AI.

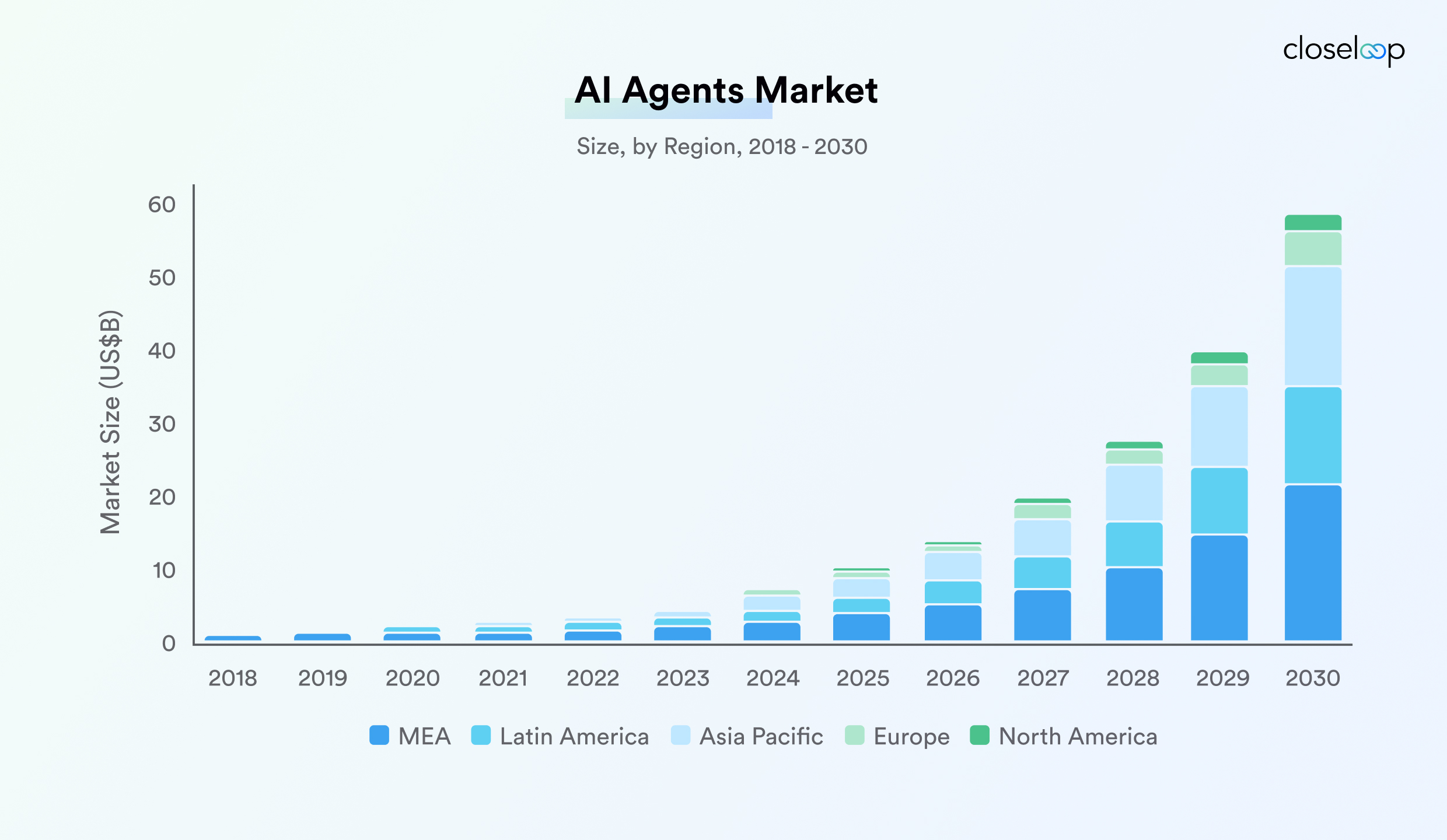
The global AI agents market, valued at USD 5.40 billion in 2024 and projected to reach USD 50.31 billion by 2030, reflects this fundamental shift toward proactive, intelligent automation. For leaders evaluating AI in data engineering, this growth underlines the maturity of AI-driven data pipeline automation across industries.
For data engineering teams struggling with pipeline failures, data quality issues, and operational overhead, AI agents offer compelling solutions that address immediate pain points while building long-term scalability. Closeloop is here to provide you with comprehensive insights into how these intelligent systems can transform your data engineering workflows from reactive maintenance into strategic competitive advantages. Our next-gen engineering services help enterprises implement AI agents for ETL and data pipelines end to end.
Key Takeaways
-
AI agents deliver 2-3x processing efficiency improvements and 60-80% error reduction in AI-driven data pipeline automation
-
Three agent types serve different needs: rule-based for validation, ML-driven for optimization, and autonomous for strategic management, real-world proof points for AI agents for data engineering
-
Implementation requires a systematic approach: pilot projects first, then gradual expansion over 12-24 months to scale automating data workflows with AI
-
Major benefits include 25-45% cost savings, automated quality management, and predictive scaling capabilities, clear benefits of AI in data engineering
-
Closeloop provides a comprehensive AI agent platform with proven industry success across financial services, healthcare, and e-commerce sectors, via AI integration services and generative AI services for AI-powered data engineering.
Understanding AI Agents in the Data Engineering Landscape
AI agents in data engineering contexts are autonomous software entities designed to perceive their environment, process information, and take actions to achieve specific objectives. Unlike traditional automation tools that follow predetermined rules, AI agents leverage machine learning in data engineering, natural language processing, and decision-making frameworks to adapt their behavior based on changing conditions and learned experiences, the backbone of data engineering automation with AI.
Key capabilities include:
-
Perception: Monitoring data flows, system performance, and environmental changes in real-time
-
Cognition: Analyzing patterns, predicting outcomes, and formulating optimization strategies
-
Action: Executing tasks, modifying configurations, and triggering workflows autonomously to support AI for data integration and transformation
-
Autonomous Learning: Continuously refining understanding of optimal system performance and developing predictive models for preventing pipeline failures
-
Adaptive Evolution: Improving effectiveness over time through experience, creating compound value for organizations, and strengthening AI agents for enterprise data management
ALSO READ: How Agentic AI works
Types of AI Agents Used in Data Engineering
To operationalize AI agents for data engineering across real pipelines, teams typically combine rule-based, ML-driven, and autonomous agents for AI-driven data pipeline automation and intelligent ETL with AI agents.
|
Agent Type |
Primary Characteristics |
Best Use Cases |
Implementation Complexity |
|
Rule-based Agents |
Conditional logic with ML optimization |
Data validation, compliance monitoring |
Low to Medium |
|
ML-driven Agents |
Pattern recognition and predictive modeling |
Anomaly detection, performance optimization |
Medium to High |
|
Autonomous Agents |
Multi-technique integration, self-directed |
End-to-end workflow management, strategic planning |
High |
The Case for Intelligent Automation in Data Engineering
Traditional data pipeline management approaches are struggling to keep pace with modern complexity and scale requirements. Intelligent automation in data engineering with AI agents offer transformative solutions that address fundamental bottlenecks while enabling more strategic approaches to data operations, a core pathway to AI-powered data engineering.
Challenges in Traditional Data Pipelines
Modern data pipelines face unprecedented complexity challenges that traditional management approaches struggle to address effectively. Data engineers routinely manage hundreds of interconnected pipeline components, each with unique dependencies, performance characteristics, and failure modes. Manual monitoring and maintenance of these systems consumes substantial next-gen engineering resources while still leaving critical gaps in coverage and response times. These realities strengthen the case for data engineering automation with AI to stabilize reliability and throughput.
Performance Impact Comparison: Traditional vs. AI-Driven Approaches
The following comparison highlights the tangible benefits of AI in data engineering for throughput, quality, and cost.
|
Performance Metric |
Traditional Approach |
AI-Driven Approach |
Improvement Factor |
|
Pipeline Processing Time |
4-8 hours average |
1.5-3 hours average |
2.5-3x faster |
|
Error Detection Time |
30-120 minutes |
2-5 minutes |
10-30x faster |
|
Resource Utilization |
60-70% efficiency |
85-95% efficiency |
1.4x improvement |
|
False Positive Alerts |
40-60% of all alerts |
5-15% of all alerts |
4-8x reduction |
|
Manual Intervention Required |
70-90% of issues |
20-40% of issues |
2-4x reduction |
|
Infrastructure Cost Optimization |
Static provisioning |
Dynamic optimization |
25-45% cost savings |
Schema drift presents another persistent challenge, occurring when data source structures change unexpectedly, potentially cascading failures throughout downstream processing systems. Traditional approaches require manual intervention to identify, diagnose, and remediate these issues, often resulting in data processing delays and incomplete dataset availability for business-critical applications. Here, AI for data integration and transformation helps detect and adapt to schema changes automatically.
Resource optimization across cloud-based data processing environments adds another layer of complexity. Data engineers must continuously balance processing performance, cost efficiency, and system reliability while managing dynamic workloads that vary significantly in resource requirements. With AI agents for ETL and data pipelines, intelligent scaling and workload placement reduce waste while improving SLO attainment, key outcomes for next-gen engineering services.
How AI Agents Reduce Bottlenecks and Enhance Data Workflow Efficiency
AI agents address traditional pipeline bottlenecks through predictive analysis and proactive intervention strategies. Rather than waiting for failures to occur, these agents continuously monitor system performance indicators, data quality metrics, and resource utilization patterns to identify potential issues before they impact production workflows. This is the core of AI-driven data pipeline automation and a practical path to AI-powered data engineering.
Intelligent resource allocation represents a significant efficiency gain area where AI agents excel. These systems analyze historical usage patterns, predict future resource requirements, and automatically adjust infrastructure scaling to optimize both performance and cost efficiency. This dynamic approach eliminates the guesswork involved in manual capacity planning while ensuring consistent performance during peak processing periods. Organizations see clear benefits of AI in data engineering when automating data workflows with AI across bursty workloads.
The Role of AI Agents in Modern DataOps
|
DataOps Practice |
Traditional Implementation |
AI Agent Enhancement |
Business Impact |
|
Continuous Monitoring |
Static dashboards and alerts |
Predictive analysis and contextual insights |
60% faster issue resolution |
|
Integration Testing |
Manual test case execution |
Automated test generation and validation |
75% reduction in testing time |
|
Version Control |
Manual deployment risk assessment |
Automated risk analysis and rollback recommendations |
50% fewer deployment failures |
|
Performance Optimization |
Periodic manual tuning |
Continuous intelligent optimization |
35% performance improvement |
DataOps methodology emphasizes continuous integration, deployment, and monitoring practices for data pipeline management. AI agents serve as force multipliers within DataOps frameworks by automating routine operational tasks while providing intelligent insights that inform strategic decision-making processes. In practice, this is intelligent automation in data engineering that operationalizes AI in data engineering with measurable outcomes, supported by our AI integration services.
Core Use Cases of AI Agents in Data Engineering
AI agents excel across multiple data engineering domains, from intelligent ingestion to comprehensive quality management. They represent real-world use cases of AI in data engineering and enable AI agents for enterprise data management at scale.
Automated Data Ingestion and Integration
AI agents revolutionize data ingestion processes by intelligently adapting to varying source system characteristics, data formats, and delivery patterns. Traditional ingestion processes often fail when encountering unexpected data structures or connection issues, requiring manual intervention and resulting in processing delays. Here, AI for data integration and transformation and AI agents for ETL and data pipelines provide adaptive, resilient ingestion.
|
Capability |
Description |
Business Value |
|
Adaptive Schema Recognition |
Automatically detects and adapts to schema changes |
90% reduction in schema-related failures |
|
Intelligent Error Recovery |
Learns from failure patterns to optimize retry strategies |
70% improvement in data availability |
|
Source Discovery |
Automatically identifies and catalogs new data sources |
50% faster new source integration |
|
Format Translation |
Dynamically converts between data formats |
80% reduction in transformation errors |
Source system discovery and cataloging represent significant areas where AI agents provide immediate value. These systems can automatically identify new data sources, analyze their structure and content patterns, and establish appropriate ingestion workflows without requiring extensive manual configuration. This capability is central to data engineering automation with AI and aligns with our next-gen engineering services.
Intelligent ETL Orchestration
ETL workflow orchestration benefits substantially from AI agent intelligence, particularly in complex environments with multiple data sources, varying processing requirements, and dynamic performance constraints. AI agents optimize processing sequences, manage resource allocation, and coordinate parallel processing workflows to maximize throughput while maintaining data quality standards. This is intelligent ETL with AI agents in action, a cornerstone of AI-powered data engineering.
|
Optimization Area |
Traditional ETL |
AI-Orchestrated ETL |
Performance Gain |
|
Processing Sequence |
Static, predefined order |
Dynamic, dependency-aware optimization |
40% faster execution |
|
Resource Allocation |
Manual capacity planning |
Intelligent, demand-based allocation |
35% cost reduction |
|
Parallel Processing |
Fixed parallelization strategies |
Adaptive parallel execution |
60% throughput improvement |
|
Error Recovery |
Manual intervention required |
Automated diagnosis and remediation |
85% faster recovery |
Dependency management becomes more sophisticated with AI agent orchestration. These systems analyze data lineage relationships, identify critical path dependencies, and optimize execution sequences to minimize processing time while ensuring data consistency. For teams scaling AI agents for data engineering, our AI integration services help address challenges in implementing AI agents for data workflows without disrupting production.
ALSO READ: ETL vs ELT - Key differences, benefits, and use cases
Data Quality and Anomaly Detection
|
Quality Dimension |
Traditional Validation |
AI Agent Approach |
Detection Accuracy |
|
Completeness |
Null value counts |
Pattern-based missing data detection |
95% accuracy |
|
Consistency |
Rule-based validation |
Multi-dimensional relationship analysis |
92% accuracy |
|
Accuracy |
Sample-based checks |
Statistical outlier detection |
89% accuracy |
|
Timeliness |
SLA monitoring |
Predictive freshness analysis |
87% accuracy |
|
Validity |
Format validation |
Context-aware validation rules |
93% accuracy |
AI agents excel at identifying data quality issues that traditional validation approaches might miss, particularly subtle pattern deviations or complex multi-dimensional anomalies. These systems develop a sophisticated understanding of normal data patterns and can detect anomalies that indicate quality issues, processing errors, or upstream system problems. This is a practical proof of AI-powered data engineering and a core driver of the benefits of AI in data engineering for reliability.
Data Governance and Compliance Automation
|
Compliance Area |
Automation Capability |
Compliance Improvement |
|
Data Lineage |
Automated tracking and documentation |
100% lineage coverage |
|
Access Controls |
Dynamic permission enforcement |
95% policy compliance |
|
Privacy Protection |
Automatic PII identification and handling |
99% privacy compliance |
|
Audit Trails |
Comprehensive activity logging |
100% audit readiness |
|
Retention Management |
Automated lifecycle management |
90% retention compliance |
Regulatory compliance requirements create substantial overhead for data engineering teams, particularly in highly regulated industries where data lineage, access controls, and audit trails must be meticulously maintained. AI agents automate many compliance-related tasks while providing comprehensive monitoring and reporting capabilities. This strengthens AI agents for enterprise data management and supports automating data workflows with AI under strict governance.
Our services align governance policies with AI in data engineering architectures to reduce audit risk and operational burden.
Designing and Implementing AI-Powered Data Pipelines
Successful AI agent implementation requires careful architectural planning and strategic integration approaches. These design considerations ensure that intelligent automation enhances existing infrastructure while providing scalable foundations for future growth. In short, this is the blueprint for data engineering automation with AI.
Key Components of an AI-Driven Data Pipeline
Successful AI-powered data pipelines require careful architectural consideration to ensure that AI agents can effectively monitor, analyze, and optimize pipeline operations. The foundation begins with a comprehensive observability infrastructure that captures detailed metrics, logs, and trace data from all pipeline components. These components operationalize AI agents for ETL and data pipelines across environments.
|
Component |
Purpose |
AI Agent Integration |
|
Observability Layer |
Comprehensive system monitoring |
Real-time performance analysis and optimization |
|
Agent Coordination Framework |
Multi-agent task distribution |
Collaborative problem-solving and resource sharing |
|
Configuration Management |
Automated deployment and versioning |
Intelligent configuration optimization |
|
Security Framework |
Access control and audit compliance |
Automated security monitoring and enforcement |
Agent coordination frameworks represent another critical architectural component, enabling multiple AI agents to collaborate effectively while avoiding conflicts or duplicated efforts. These frameworks establish communication protocols, task distribution strategies, and coordination mechanisms that ensure AI agents work together harmoniously. This is foundational to AI-driven data pipeline automation at enterprise scale.
Best Practices for Integrating AI Agents with Existing Infrastructure
|
Integration Approach |
Implementation Time |
Risk Level |
Long-term Benefits |
|
Big Bang Migration |
6-12 months |
High |
Maximum transformation impact |
|
Gradual Rollout |
12-24 months |
Medium |
Reduced implementation risk |
|
Pilot-First Strategy |
3-6 months initial |
Low |
Proven value before expansion |
|
Hybrid Implementation |
9-18 months |
Medium |
Balanced risk and benefit |
Legacy system AI integration requires careful planning to ensure that AI agents can effectively interact with existing data processing infrastructure without disrupting established workflows. This often involves developing API interfaces, message queuing systems, and data exchange protocols that enable AI agents to monitor and control existing systems. A pilot-first path de-risks challenges in implementing AI agents for data workflows while demonstrating quick wins in AI in data engineering.
Scalability Considerations and Cloud-Native Approaches
|
Scalability Factor |
Traditional Architecture |
Cloud-Native AI Agents |
Scalability Improvement |
|
Resource Elasticity |
Manual scaling decisions |
Automatic demand-based scaling |
5-10x faster scaling response |
|
Geographic Distribution |
Single-region deployment |
Multi-region agent coordination |
3-5x improved global performance |
|
Service Isolation |
Monolithic deployments |
Microservices-based agents |
2-3x improved fault tolerance |
|
Resource Utilization |
Static resource allocation |
Dynamic resource optimization |
40-60% improved efficiency |
Cloud-native architectures provide natural advantages for AI agent deployment, offering elastic scaling capabilities, managed services, and distributed processing frameworks that support sophisticated agent implementations. These patterns are central to intelligent automation in data engineering and unlock sustainable scale for AI agents for data engineering.
Evaluating and Selecting the Right AI Agents
Choosing appropriate AI agents requires a systematic evaluation of technical capabilities, integration requirements, and long-term strategic alignment. This section provides frameworks for making informed decisions that optimize both immediate value and future scalability. When evaluating solutions for AI agents for data engineering and AI-powered data engineering, prioritize vendor fit, interoperability, and TCO across real production workloads.
Criteria for Choosing AI Data Engineering Tools
|
Evaluation Criteria |
Weight |
Key Assessment Questions |
|
Technical Capabilities |
25% |
Does the agent support is required ML algorithms and decision-making frameworks? |
|
Integration Complexity |
20% |
How easily does it integrate with existing infrastructure? |
|
Scalability |
20% |
Can it handle future growth without architectural changes? |
|
Vendor Ecosystem |
15% |
Is the vendor reliable with strong support and a roadmap? |
|
Total Cost of Ownership |
10% |
What are the complete costs, including implementation and maintenance? |
|
Security & Compliance |
10% |
Does it meet security and regulatory requirements? |
Technical capability assessment represents the primary evaluation criterion when selecting AI agents for data engineering applications. This includes analyzing agent learning algorithms, decision-making frameworks, and integration capabilities to ensure alignment with specific use case requirements.
Open-Source vs. Proprietary AI Agent Ecosystems
|
Factor |
Open-Source Solutions |
Proprietary Solutions |
Hybrid Approach |
|
Initial Cost |
Low (development time) |
High (licensing fees) |
Medium (selective licensing) |
|
Customization |
High flexibility |
Limited customization |
Selective customization |
|
Support Quality |
Community-based |
Professional support |
Mixed support models |
|
Implementation Time |
6-12 months |
3-6 months |
4-8 months |
|
Vendor Lock-in Risk |
None |
High |
Controlled |
|
Feature Richness |
Variable |
Comprehensive |
Best of both |
Open-source AI agent solutions provide significant advantages in terms of customization flexibility, transparency, and cost control. Organizations can modify agent behavior, integrate with custom systems, and avoid vendor lock-in while maintaining complete control over their intelligent automation implementations. Proprietary options may accelerate time-to-value for AI agents for enterprise data management, while hybrid models often balance speed with the flexibility needed for AI for data integration and transformation.
Selection should map to your roadmap for intelligent automation in data engineering and the operating model for AI-powered data engineering.
Integration and Interoperability Challenges
|
Challenge |
Impact Level |
Solution Strategy |
Implementation Effort |
|
API Compatibility |
High |
Develop translation layers and adapters |
Medium |
|
Data Format Standardization |
Medium |
Implement common data schemas |
High |
|
Security Model Alignment |
High |
Create unified security frameworks |
High |
|
Performance Impact |
Medium |
Optimize communication protocols |
Medium |
API compatibility represents a fundamental integration consideration, particularly in environments with diverse systems and platforms. Organizations should evaluate agent API capabilities, data format support, and protocol compatibility to ensure smooth integration with existing infrastructure components. Addressing these challenges in implementing AI agents for data workflows is essential to scaling AI-driven data pipeline automation safely.
Measurable Benefits and Business Impact
AI agents deliver quantifiable improvements across operational efficiency, cost optimization, and strategic capabilities. Understanding these measurable benefits helps organizations build compelling business cases and track implementation success. These are tangible benefits of AI in data engineering that validate AI-powered data engineering beyond proofs of concept.
Quantifiable Efficiency Gains and Error Reduction
|
Benefit Category |
Baseline Performance |
AI Agent Performance |
Improvement Factor |
Annual Value ($M) |
|
Processing Time Reduction |
8 hours average |
2.5 hours average |
3.2x faster |
$2.1 |
|
Error Rate Reduction |
15% error rate |
3% error rate |
5x improvement |
$1.8 |
|
Infrastructure Cost Savings |
$500K annual |
$325K annual |
35% reduction |
$0.175 |
|
Engineering Time Savings |
60% on maintenance |
20% on maintenance |
3x efficiency |
$1.2 |
|
Data Quality Improvement |
80% accuracy |
95% accuracy |
1.2x improvement |
$0.9 |
Organizations implementing AI agents in data engineering workflows typically observe substantial efficiency improvements across multiple operational dimensions. Pipeline processing time reductions of 30-50% are commonly reported as AI agents optimize resource allocation, eliminate bottlenecks, and improve parallel processing coordination. This reflects the impact of AI-driven data pipeline automation and AI agents for ETL and data pipelines in production.
Error reduction represents another significant benefit area, with AI agents typically achieving 60-80% reductions in data quality issues and pipeline failures through predictive analysis and proactive intervention. Combining machine learning in data engineering with closed-loop remediation is central to data engineering automation with AI.
Enhanced Decision-Making and Data Democratization
|
Impact Area |
Traditional Approach |
AI Agent Enhancement |
Business Value |
|
Data Availability |
92% uptime |
99.2% uptime |
$450K annual revenue protection |
|
Decision Speed |
2-3 days for insights |
4-6 hours for insights |
40% faster business decisions |
|
Self-Service Analytics |
30% user adoption |
75% user adoption |
$800K productivity gains |
|
Predictive Accuracy |
65% forecast accuracy |
87% forecast accuracy |
$1.2M planning improvements |
AI agents contribute to improved decision-making capabilities by ensuring higher data quality, reducing data latency, and providing more comprehensive data availability across the organization. These improvements enable business users to access timely, accurate information that supports more effective decision-making processes. In practice, this enables AI agents for enterprise data management and accelerates automating data workflows with AI across teams.
Common Pitfalls and How to Overcome Them
Successful AI agent implementation requires awareness of potential challenges and proactive mitigation strategies. These common pitfalls and their solutions help organizations avoid costly mistakes while maximizing implementation success. Many of these roadblocks reflect challenges in implementing AI agents for data workflows, especially when scaling from pilots to production in AI-powered data engineering.
Data Security and Privacy Concerns with AI Automation
|
Security Risk |
Risk Level |
Mitigation Strategy |
Implementation Priority |
|
Unauthorized Data Access |
High |
Multi-factor authentication and role-based access |
Critical |
|
Data Exposure |
High |
End-to-end encryption and data masking |
Critical |
|
Audit Trail Gaps |
Medium |
Comprehensive logging and monitoring |
High |
|
Configuration Vulnerabilities |
Medium |
Automated security scanning |
High |
|
Agent Compromise |
Low |
Isolated execution environments |
Medium |
AI agents require comprehensive access to data systems and infrastructure to perform their optimization and automation functions effectively. This access creates potential security vulnerabilities if not properly managed through access controls, encryption, and audit mechanisms. Robust controls enable AI agents for enterprise data management without risking sensitive assets and align security baselines with AI-driven data pipeline automation.
Avoiding Overfitting and Model Drift in AI Agents
|
Performance Metric |
Monitoring Frequency |
Alert Threshold |
Remediation Action |
|
Prediction Accuracy |
Daily |
<85% accuracy |
Model retraining |
|
Feature Drift |
Weekly |
>15% drift |
Feature engineering review |
|
Data Distribution |
Real-time |
>2 standard deviations |
Input validation update |
|
Performance Degradation |
Continuous |
>10% decline |
Immediate investigation |
Model overfitting occurs when AI agents become too specialized for historical patterns and lose their ability to adapt to changing conditions or handle novel situations effectively. This challenge requires implementing robust validation frameworks, diverse training datasets, and continuous learning mechanisms. Treat this as core MLOps hygiene for machine learning in data engineering so you can sustain automating data workflows with AI across changing workloads.
Organizational Change Management
|
Success Factor |
Importance Level |
Implementation Strategy |
|
Leadership Support |
Critical |
Executive sponsorship and clear communication |
|
Skills Development |
High |
Comprehensive training and certification programs |
|
Process Integration |
High |
Gradual workflow integration and feedback loops |
|
Cultural Adaptation |
Medium |
Success story sharing and peer mentoring |
Technical implementation success often depends on effective change management that helps organizations adapt to new workflows, responsibilities, and operational approaches. Data engineering teams must develop new skills for monitoring, configuring, and optimizing AI agents while maintaining their existing technical responsibilities. This enables sustainable scale for AI-powered data engineering and reduces friction when automating data workflows with AI.
Closeloop: Enabling Next-Generation Data Engineering with AI Agents
Closeloop represents a comprehensive platform designed specifically for intelligent data engineering automation through integrated AI agents. This section explores how Closeloop's innovative approach addresses real-world challenges while delivering measurable business value. Our approach operationalizes AI-driven data pipeline automation for regulated and high-scale environments.
Closeloop delivers a new generation of intelligent digital transformation engineering platforms that harness AI agents for comprehensive pipeline automation and optimization. The platform embodies a self-managing data infrastructure that adapts continuously to changing requirements while maintaining optimal performance, reliability, and cost efficiency.
Core capabilities include automated workflow orchestration with processing time reduction, smart data quality solutions achieving fewer quality issues, and predictive resource management delivering cost optimization. We implement AI agents for ETL and data pipelines end to end through AI integration services and generative AI services and solutions, aligned to enterprise governance.
The Future of AI Agents in Data Engineering
The evolution of AI agents promises increasingly sophisticated capabilities that will reshape data engineering practices fundamentally. Understanding these emerging trends helps organizations prepare for the future of artificial intelligence and automation opportunities. These trajectories define the future of AI in data engineering and the next wave of AI agents for enterprise data management.
Trends to Watch: Generative AI, Edge Intelligence, and Hyperautomation
|
Technology Trend |
Current Maturity |
Expected Impact |
Timeline |
|
Generative AI |
Medium |
Synthetic data generation, automated code creation |
2025-2026 |
|
Edge Intelligence |
Low-Medium |
Real-time processing, reduced latency |
2026-2028 |
|
Hyperautomation |
Medium-High |
End-to-end process automation |
2025-2027 |
|
Quantum Computing |
Low |
Complex optimization, advanced analytics |
2030+ |
Generative AI capabilities will enable AI agents to create new solutions, generate synthetic data for testing purposes, and develop novel approaches to complex data processing challenges. These creative capabilities will extend agent utility beyond optimization of existing processes toward innovation and development of entirely new approaches to data engineering challenges. As these trends mature, organizations will expand from pilots to platform-level AI-powered data engineering with clear roadmaps for AI-driven data pipeline automation.
Skills and Teams Needed for Successful Adoption
|
Skill Category |
Current Importance |
Future Importance |
Development Priority |
|
AI/ML Expertise |
Medium |
Critical |
High |
|
Systems Architecture |
High |
Critical |
Medium |
|
Strategic Planning |
Medium |
High |
High |
|
Change Management |
Low |
High |
Medium |
Technical skills required for successful AI agent adoption include an understanding of machine learning principles, distributed systems architecture, and agent coordination frameworks. Data engineering teams will need to develop expertise in configuring, monitoring, and optimizing AI agents while maintaining their traditional technical competencies. These capabilities underpin AI-powered data engineering and enable automating data workflows with AI across complex environments.
Getting Started: Actionable Steps Toward Intelligent Automation
Successful AI agent adoption requires systematic planning and phased implementation approaches that balance immediate value with long-term transformation objectives. This practical roadmap provides concrete steps for beginning your intelligent automation journey. Treat this as the on-ramp to data engineering automation with AI and scalable AI in data engineering.
Readiness Assessment and Laying the Foundation
|
Assessment Area |
Evaluation Criteria |
Required Actions |
|
Technical Infrastructure |
APIs, monitoring, and data quality |
Infrastructure upgrades |
|
Team Capabilities |
AI/ML skills, system expertise |
Training and hiring |
|
Data Governance |
Quality frameworks, compliance |
Governance improvements |
|
Change Management |
Leadership support, culture |
Change strategy development |
Organizational readiness assessment represents the crucial first step toward successful AI agent implementation, requiring a comprehensive evaluation of technical infrastructure, team capabilities, and business objectives. This assessment should identify existing automation capabilities, infrastructure readiness, and skill gaps that must be addressed before AI agent deployment can begin effectively. It aligns architecture for AI agents for ETL and data pipelines and prepares controls for AI agents for enterprise data management.
Quick Wins: Piloting AI Agents for Data Tasks
|
Pilot Phase |
Duration |
Success Criteria |
Resource Requirements |
|
Phase 1: Proof of Concept |
4-6 weeks |
Demonstrate basic functionality |
2-3 engineers, limited budget |
|
Phase 2: Limited Production |
8-12 weeks |
Measurable efficiency gains |
3-5 engineers, moderate budget |
|
Phase 3: Expanded Deployment |
12-16 weeks |
Full operational integration |
5-8 engineers, full budget |
Initial pilot implementations should focus on well-defined, non-critical use cases that provide clear success metrics while minimizing implementation complexity and business risk. Common pilot scenarios include automated data quality monitoring, simple ETL optimization, and routine system maintenance tasks that provide immediate value while building organizational confidence. These pilots validate the benefits of AI in data engineering and de-risk challenges in implementing AI agents for data workflows.
Closeloop supports pilot-to-production paths for AI-driven data pipeline automation through next-gen engineering services, accelerating time-to-value without disrupting operations.
Building a Long-Term Roadmap for AI-Powered Data Engineering
|
Phase |
Timeline |
Objectives |
Expected ROI |
|
Foundation |
Months 1-6 |
Infrastructure preparation, team training |
Break-even |
|
Optimization |
Months 7-18 |
Process automation, efficiency gains |
150-200% ROI |
|
Transformation |
Months 19-36 |
Strategic automation, innovation |
250-400% ROI |
|
Innovation |
Months 37+ |
Advanced capabilities, competitive advantage |
400%+ ROI |
Strategic roadmap development requires balancing immediate operational improvements with longer-term transformation objectives that leverage advancing AI agent capabilities. Successful roadmaps typically progress through phases that gradually expand agent responsibilities while building organizational expertise and confidence in intelligent automation approaches. This phased path institutionalizes AI-powered data engineering and scales AI-driven data pipeline automation with clear KPIs.
Conclusion: The Strategic Advantage of Adopting AI Agents in Data Engineering
The integration of AI agents into data engineering workflows represents a fundamental transformation that delivers measurable benefits: 2-3x processing efficiency improvements, 60-80% error rate reductions, and 25-45% cost optimizations. As data volumes reach unprecedented scales and real-time insights become business imperatives, traditional manual pipeline management approaches are no longer sustainable. For data engineering leaders, the imperative is clear: begin intelligent automation adoption now through targeted pilot implementations that deliver immediate value while establishing foundations for comprehensive transformation. This is the moment to operationalize AI agents for data engineering, AI agents for ETL and data pipelines, and broader data engineering automation with AI.
Organizations that successfully harness AI agents will create self-managing, self-optimizing data ecosystems that transform data from operational cost into a strategic asset. The question is not whether AI agents will revolutionize data engineering, but how quickly organizations can adapt to leverage these transformative capabilities for sustainable competitive advantage.
Closeloop supports end-to-end adoption with AI integration services, generative AI services and solutions, and next-gen engineering services, turning AI in data engineering from pilots into a durable platform capability. Talk to Closeloop’s data engineering team.
Author

Saurabh Sharma

VP of Engineering
VP of Engineering at Closeloop, a seasoned technology guru and a rational individual, who we call the captain of the Closeloop team. He writes about technology, software tools, trends, and everything in between. He is brilliant at the coding game and a go-to person for software strategy and development. He is proactive, analytical, and responsible. Besides accomplishing his duties, you can find him conversing with people, sharing ideas, and solving puzzles.
Stay abreast of what's trending in the world of technology
Cost Breakdown to Build a Custom Logistics Software: Complete Guide
Global logistics is transforming faster than ever. Real-time visibility, automation, and AI...

Logistics Software Development Guide: Types, Features, Industry Solutions & Benefits
The logistics and transportation industry is evolving faster than ever. It’s no longer...

From Hurdle to Success: Conquering the Top 5 Cloud Adoption Challenges
Cloud adoption continues to accelerate across enterprises, yet significant barriers persist....

Gen AI for HR: Scaling Impact and Redefining the Workplace
The human resources landscape stands at a critical inflection point. Generative AI in HR has...

